
Data Science против Machine Learning
 5 мин
5 мин
 9785
9785  5 Авг 2020
5 Авг 2020 
Основатель и Генеральный директор, SF Education

Получите 3-х дневный бесплатный демо-период
Введение
Недавно мы с командой наткнулись на то, что не смогли договориться, кто или что такое «девелопер». Один сказал, что это предприниматель, который занимается созданием новой недвижимости; другой – что так модно назвать программного разработчика; финансовый директор сказал, что это аналитик, разрабатывающий стратегии развития компании, а рекламщик – фанат фотографии – с пеной у рта доказывал, что это проявитель для снимков.
Договориться у нас так и не получилось, а спор, как снежный ком, стал расти. В итоге мы узнали 4 значения слова «джоббер», пришлось объяснить девушке из финансового отдела, что «тестер» – это не пробный экземпляр духов в магазине, а «ресечер» – это помощник рекрутера.
Если вы подумали, что ошиблись: и вместо портала о финансах и аналитике попали в лингвистический онлайн-институт, то это не так. Вы попали как раз по адресу.
Если у нас возникли небольшие разногласия и вопросы по поводу современных названий профессий, то, возможно, у кого-то из вас тоже появлялись подобные вопросы, которые некогда было прояснить.
В этом мы решили вам помочь. Мы будем постепенно вводить вас в курс дела и освещать самые популярные и непонятные по названиям специальности. Вдруг вы всегда мечтали стать, например, трейдером, но пугающее название даже не давало Вам помыслить в ту сторону.
С этого дня SF Education – это единственный финансовый онлайн-институт с лингвистическим уклоном!))
Data Science vs Machine Learning
Сегодня поговорим о науке о данных и машинном обучении. А точнее об ученых по данным и инженерах машинного обучения (к специалистам, создающим лекции для станков ЧПУ, эта профессия не имеет никакого отношения).
Кажется, что даже у современных компаний бывает путаница в том, что из себя представляют две эти профессии и какие требования необходимо выдвигать кандидатам.
Сегодня мы хотим пролить свет на то, почему профессии разделены и где роли специалистов могут пересекаться.
Вообще, погруженные достаточно глубоко в IT-сферу люди быстро осознают, что эти области очень похожи, но в то же время отличаются настолько, что требуют уникальных наборов знаний и умений.
Короче говоря, наука о данных – это исследование, построение и интерпретация созданной модели, в то время как машинное обучение – своего рода инструмент для создания этой модели.
– Кто такой Data Scientist?
– Статистик?
– Типа того.
Наука данных, в самом общем смысле – это область автоматизированной статистики в форме моделей, которые помогают в классификации и прогнозировании результатов.
Вот основные навыки, необходимые для работы с данными:
- Языки программирования: Python или R;
- SQL;
- Алгоритмы машинного обучения.
Языки программирования необходимы для целостного исследования данных. С помощью программных манипуляций можно выудить из Big Data (да и не очень big data) много больше выводов и закономерностей, чем глядя двумя даже самыми умными глазами на тысячестрочные таблицы. К тому же, это универсальный профессиональный язык. На нем можно общаться с коллегами. Но это высший уровень мастерства.
SQL, может показаться, больше нужен аналитикам. Но ученые по данным и есть своего рода аналитики. Если Вы работаете в бизнес-среде, то большинство наборов данных на блюдечке не предоставляются и приходится создавать свои собственные – с помощью SQL. Сейчас существует множество систем, использующих SQL, например, PostgreSQL, MySQL, Microsoft SQL Server T-SQL и Oracle SQL. Это схожие формы одного и того же языка запросов, размещенные на разных платформах. Поскольку они очень похожи (по крайней мере, в базовом наборе функций), наличие в активе любого из них полезно и поможет легко адаптироваться к иной форме SQL. Если вы хотите изучить SQL, то рекомендуем записаться на наш открытый онлайн-курс «Аналитика с SQL и R».
Алгоритмы машинного обучения позволяют автоматизировать многие процессы, которые не под силу человеку. Машинное обучение – неотъемлемая часть науки о данных. Методами, входящими в область ML должен обладать каждый Data Scientist, считающий себя профессионалом.
В целом, Data Scientist может многое. Но основными функциями являются:
- Сбор и очистка данных;
- Визуализация данных;
- Работа с методами неструктурированного управления данными;
- Разработка программных компонентов для автоматизации процессов;
- Построение моделей и прогнозирование.
Кто такой инженер машинного обучения?
Machine Learning – это область, состоящая из целого набора методов, позволяющих изучать и обрабатывать наборы данных без вмешательства человека. Это достигается с помощью сложных алгоритмов и методов, таких как регрессия, кластеризация, метод Байеса и многое другое.
Инженер машинного обучения создает полезную модель или программу, автономно тестирующую множество решений на основе имеющихся данных. А затем находящую наилучшее решение. Созданные с помощью методов машинного обучения алгоритмы способны выдавать аргументированные решения и делать прогнозы по сложным вопросам.
Иногда модель, созданная Data Scientist бывает довольно статичной. Если данных очень мало, то их нужно как-то генерировать, а если их очень много, то обработать их вручную проблематично и не особо эффективно. В таком случае инженер может помочь автоматически обучить и оценить ту же модель.
Навыки, необходимые для инженеров машинного обучения:
- Основы информатики;
- Статистическое моделирование;
- Оценка данных и моделирование;
- Понимание и применение алгоритмов;
- Обработка естественного языка;
- Проектирование архитектуры данных.
С первого взгляда, науку о данных и машинное обучение можно рассматривать как взаимозаменяемые области. Однако, это не так. Скорее это две пересекающиеся сферы, но при этом существующие отдельно друг о друга.
То есть как область Machine Learning активно развивается в отрыве от Data Science, так и DS включает в себя другие разделы.
На рисунке показано, как соотносятся две эти области.
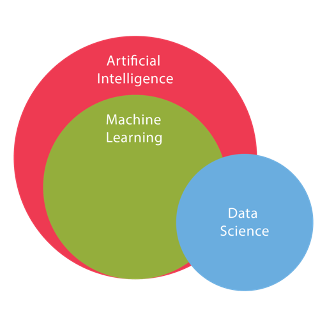
Сходства
Зачастую ученые по данным хорошо знакомы с методами машинного обучения и сами выполняют роль инженеров ML.
Все это благодаря тому, что и те, и другие имеют в своем арсенале следующие основные навыки:
- Python или R;
- SQL;
- GitHub;
- Знание концепции обучения и анализа данных.
И инженеры машинного обучения, и ученые о данных занимаются проектированием, будь то ученый, запрашивающий базу данных с использованием SQL, или инженер машинного обучения, использующий SQL, для обучения модели.
Обе вакансии требуют умение программирования на высоком уровне и знание языка Python (или R) и, как правило, системы контроля версий, совместного использования кода и запросов извлечения через GitHub. Рекомендуем записаться на наш открытый онлайн-курс «Первый код на Python», если хотите освоить Python.
Оба специалиста имеют дело с моделями данных, поэтому должны уметь применять основные методы и алгоритмы анализа и прогнозирования (Метод главных компонент; метод наименьших квадратов; построение регрессии; методы кластеризации, типа k-средних; использование нейронных сетей различной конфигурации; деревья принятия решений и многое другое).
Различия
Основное отличие заключается в реализуемых процессах и конечных результатах. Наука о данных охватывает, как говорят математики, несчетное множество задач, посредством обработки, очистки, анализа, прогнозирования и интерпретации результатов, а машинное обучение – решает ограниченный круг проблем с уже очищенными, обработанными данными.
В чем особенности каждой области?
Наука о данных
– фокусируется на статистике и алгоритмах;
– неконтролируемых и контролируемых алгоритмах;
– регрессии и классификации;
– интерпретирует результаты;
– представляет и сообщает результаты.
Машинное обучение
– основной упор на разработку программного обеспечения и программировании;
– автоматизация;
– масштабирование;
– планирование;
– включение результатов модели в таблицу / склад / пользовательский интерфейс.
Также существует некоторое различие в подходах к образованию. Специалисты по данным, например, могут сосредоточиться на получении знаний в статистике, математике или актуарной науке, в то время как инженер по машинному обучению будет уделять основное внимание изучению аспектов разработки программного обеспечения.
Резюме
Вопрос разделения профессиональных навыков стоит довольно остро. Конечно, работодатели хотят видеть в своих коллективах «универсальных» солдат, способных и компьютер обучить, и компанию озолотить. (и стены в зале совещаний покрасить и коробки в архив отнести…).
Поэтому молодые специалисты стараются развиваться в разных сферах, чтобы быть более конкурентоспособными и востребованными.
Из-за этого грань между разными специальностями размывается и уже не разберешь, что должен делать, например, аналитик данных, а что менеджер по продажам.
Мы, конечно, за многогранность и саморазвитие! Но мешать котлеты с мухами – не самая лучшая идея.
Смешивание двух сфер деятельности, как например, науку о данных и машинное обучение, лишь обедняет каждое понятие, занижает значимость и ухудшает квалификацию специалистов (все хотят приписать себе ту или иную модную специальность, а вот владеют ли они ей на самом деле…). К сожалению, ответ на этот вопрос все утаивают.
Мы стремимся к тому, чтобы наши студенты полностью владели всеми необходимыми навыками и знаниями для успешной карьеры.
Если Вам интересна история ваших специальностей, особенности и отличия от смежных сфер деятельности, то пишите в комментариях все, о чем хотелось бы узнать. Мы вам все расскажем!
Автор: Алексанян Андрон, эксперт SF Education


