
Лучшие библиотеки языка R
 7 мин
7 мин
 4932
4932  7 Авг 2020
7 Авг 2020 
Основатель и Генеральный директор, SF Education

Пролог
Ранее у нас уже был цикл статей о лучших библиотеках языка Python:
Теперь настало время поговорить на аналогичную тему, но переключив свое внимание на язык R. Даже в обзорах на питоновские библиотеки мы не раз ссылались на различные пакеты R, так как во многом эти два языка друг с другом конкурируют.
Однако, индустрия анализа данных активно развивается в наши дни и было бы неплохо владеть обоими инструментами, хотя бы на базовом уровне. Тем более, намного удобней «жонглировать» языками программирования в зависимости от задачи – это позволит сэкономить время и облегчить себе жизнь.
Простой пример – возникает нетривиальная задача парсинга веб-страниц. Вы знакомы с пакетом rvest, httr и прочими в языке R, а как решить такую задачу в Python – не имеете представления. По какому пути пошли бы Вы: воспользовались бы своими знаниями или пошли бы штудировать с нуля пакеты питона для работы с http? Думаю, ответ очевиден… Но хватит слова – давайте к делу!
1. readr
Первое, с чего начнется процесс любой аналитики – загрузка данных в рабочую область. Именно для этого и предназначен пакет readr – периферийная библиотека семейства пакетов tidyverse.
Кто не в теме: tidyverse – флагманская библиотека языка R, разработанная для комплексного анализа данных и Data Science. Входящие в экосистему tidyverse пакеты позволяют производить комплексную обработку данных – начиная от загрузки данных из различных источников и заканчивая построением визуализаций.
Итак, возвращаясь непосредственно к readr, – это пакет, который позволяет пользователю загружать табличные данные из самых разных источников. Например, csv или текстовые файлы.
У данного пакета есть ряд неоспоримых преимуществ, которые выгодно выделяют его среди конкурентов (да, в языке R есть еще большое количество сторонних пакетов для такого же рода задач). Давайте рассмотрим небольшой пример.
Допустим, у нас есть набор данных из трех строк с заголовками. Первое поле – числа, второе – текст.
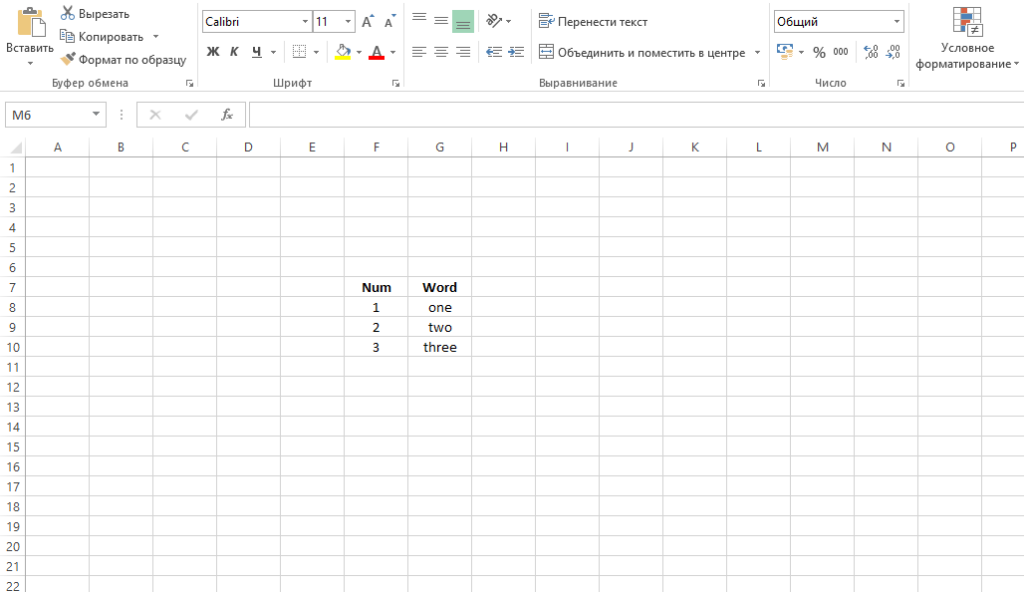
Посмотрим, что мы получим, если загрузим такую незамысловатую таблицу с помощью стандартной функции read.table(). Загружать будем из txt-файлика.
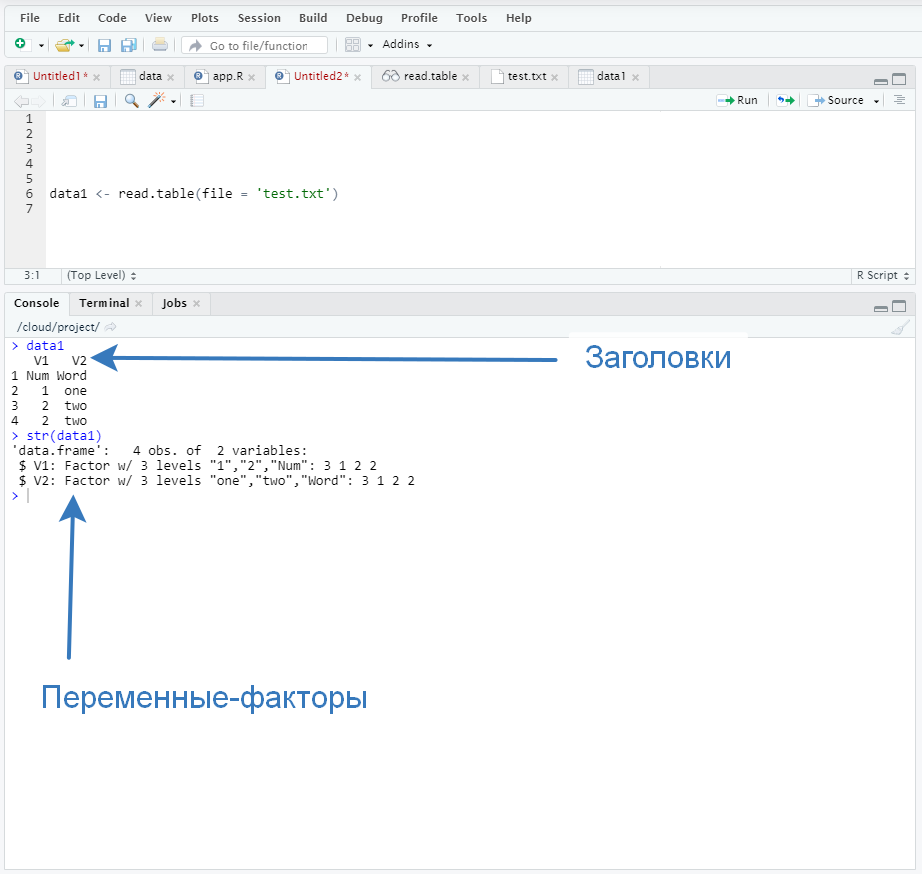
На картинке видно, что у нас возникло сразу две проблемы:
- Наши заголовки Num и Word считались как часть таблицы, а вместо заголовков в таблице стоит V1 и V2.
- Наши данные загрузились как факторы (специальный тип данных), что очень неудобно. Мы же должны были получить числа и текст.
Теперь посмотрим, как нужно переписать эту функцию, чтобы получить правильный результат.
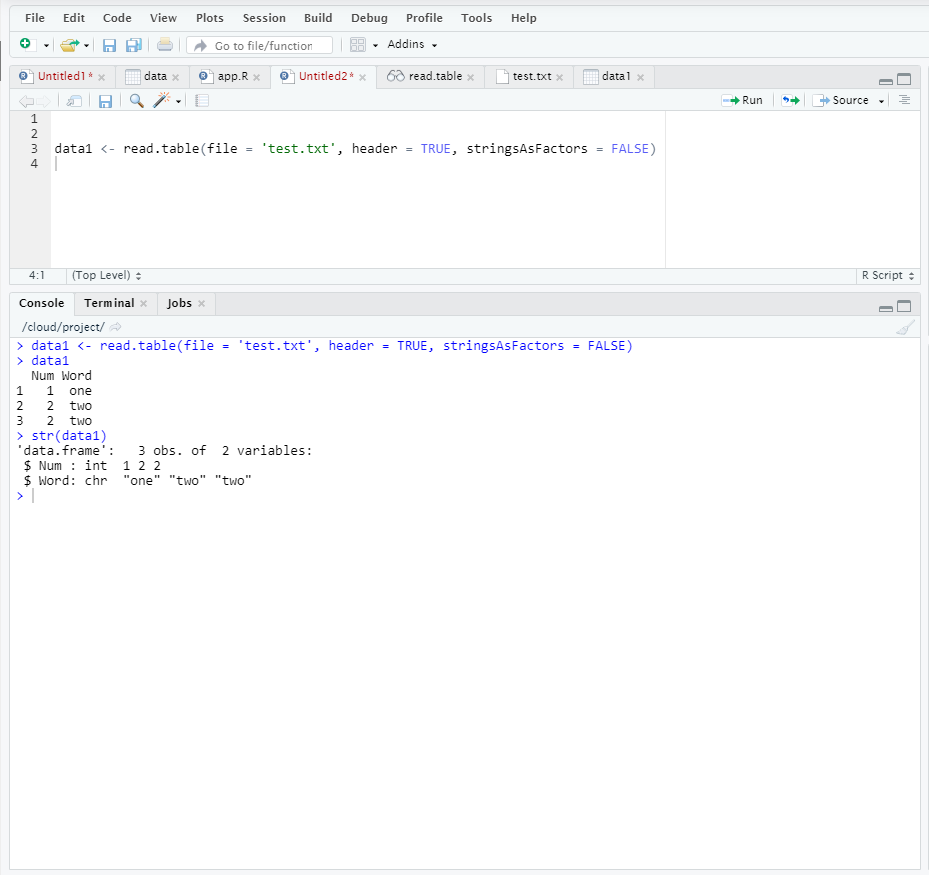
Мы добавили несколько аргументов к исходной функции, сообщая ей, что у нас есть заголовки в таблице, а также что не нужно переводить текстовые данные в факторы. После такой кастомизации (т.е. подстройки функции под свою задачу) мы получаем наконец верный результат.
А теперь смотрим, как бы с этой задачей справилась библиотека readr.
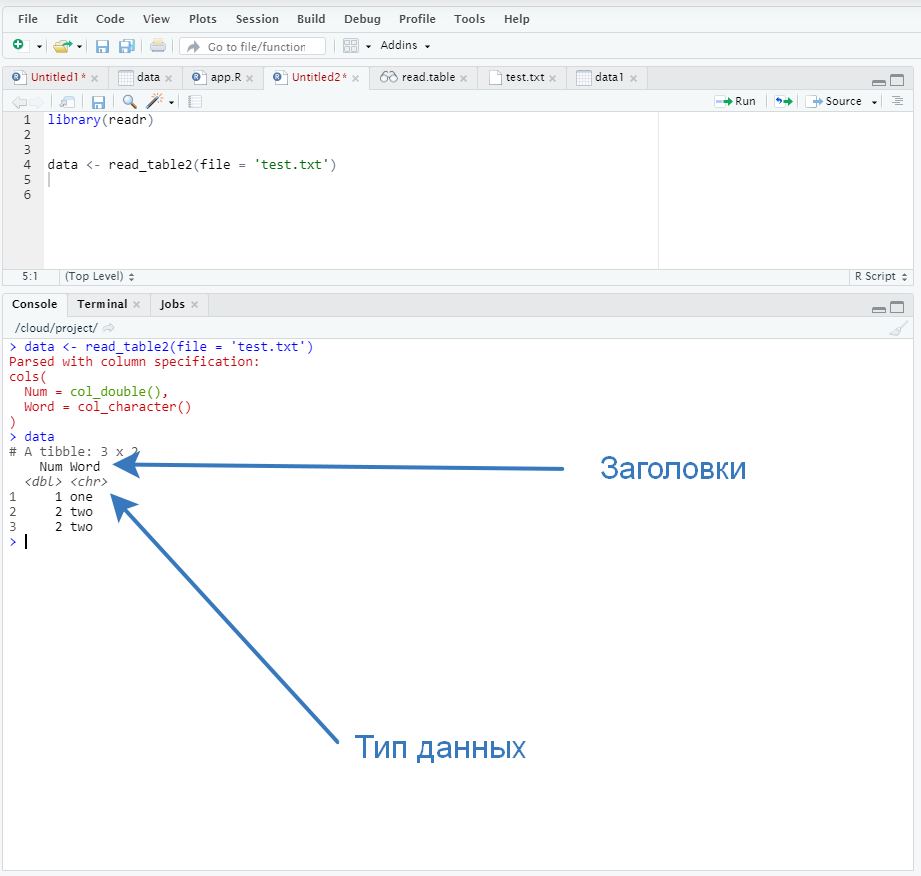
Никаких дополнительных аргументов – все загружается четко прям «из коробки». Это удобно – система сама определяет тип переменных, а все дефолтные параметры (т.е. параметры, которые имеют некоторое значение по умолчанию, но их можно поменять) выставлены грамотно.
Само собой, есть и слабые стороны библиотеки. Для примера могу рассказать, что доставляет неудобства конкретно мне.
Дело в том, что пакет readr спроектирован таким образом, что для каждого формата файла (например, txt или csv) есть отдельная функция. Это правильно, но это еще не все. Для разных разделителей тоже функции разные. Поясню. Вот в нашем примере, мы использовали функцию read_table2(). Почему именно 2, а не просто read_table()? А потому что функция read_table() более строгая – она предполагает одинаковый размер каждой строки и накладывает определенные ограничения на разделители столбцов. И в нашем случае она не подходит. А если бы нам нужно было использовать запятые, точки с запятой или другие знаки в качестве разделителей, то нам нужно было бы использовать read_delim(). В общем, к чему это все я, – с одной стороны, такое четкое разделение идет на пользу, т.к. каждая функция четко знает свой маневр. Однако, есть и минусы – для исследователя намного проще передать один дополнительный параметр в функцию о том, какие разделители нужно использовать, чем на каждую ситуацию использовать новую функцию. Но это спорный вопрос, да и на вкус и цвет, как говориться…
Еще пару слов о пакете readr. Помимо чтение данных, с помощью него можно и сохранять различного рода информацию аналогичным образом. Плюс прям в пакете доступно большое количество функций для кастомизации загрузки-выгрузки: форматирование столбцов, явное задание типов данных, выбор столбцов для загрузки и другое.
Примечание. Внимательный читатель мог обратить внимание, что мы обсуждали только табличные данные. Но есть же еще большое количество источников – всякие базы данных, json, xml и многое другое.
Совершенно верно, но для загрузки такого вида данных используются дополнительные пакеты. Они не входят в состав readr, но рекомендуются в официальной документации. Например, пакет readxl для загрузки xls и xlsx файлов.
2. tidyr
Что делает исследователь, после того, как данные загружены в систему? Начинает расчеты и анализ? Хотелось бы, но нет. Если только в параллельной вселенной. А в нашем жестоком индустриальном мире мы сначала делаем очистку данных. Очистку от пропусков, очистку от выбросов, очистку от откровенного мусора даже иногда… И весь этот “tidying” берет на себя практически одноименный пакет – tidyr.
Если Вы так или иначе следите за нашими вебинарами/марафонами/статьями, связанными с аналитикой, программированием и языком R в частности, то Вы уже неоднократно слышали про этот пакет. При разборе чуть ли не каждой задачи мы используем пару-тройку функций из этого пакета, и не зря – в реальных задачах редко Вам предоставляют уже очищенные и готовые к обработке наборы данных. Иногда это вообще просто хаотичная свалка данных, и диву даешься, как вообще это все в табличном виде представили. Наша же задача – минимальными трудо- и времязатратами сделать из этого «информационного набора» самый настоящий «эстетичный датафрейм». Рассмотрим пример.
Итак, пусть у нас есть «неаккуратный» датасет.
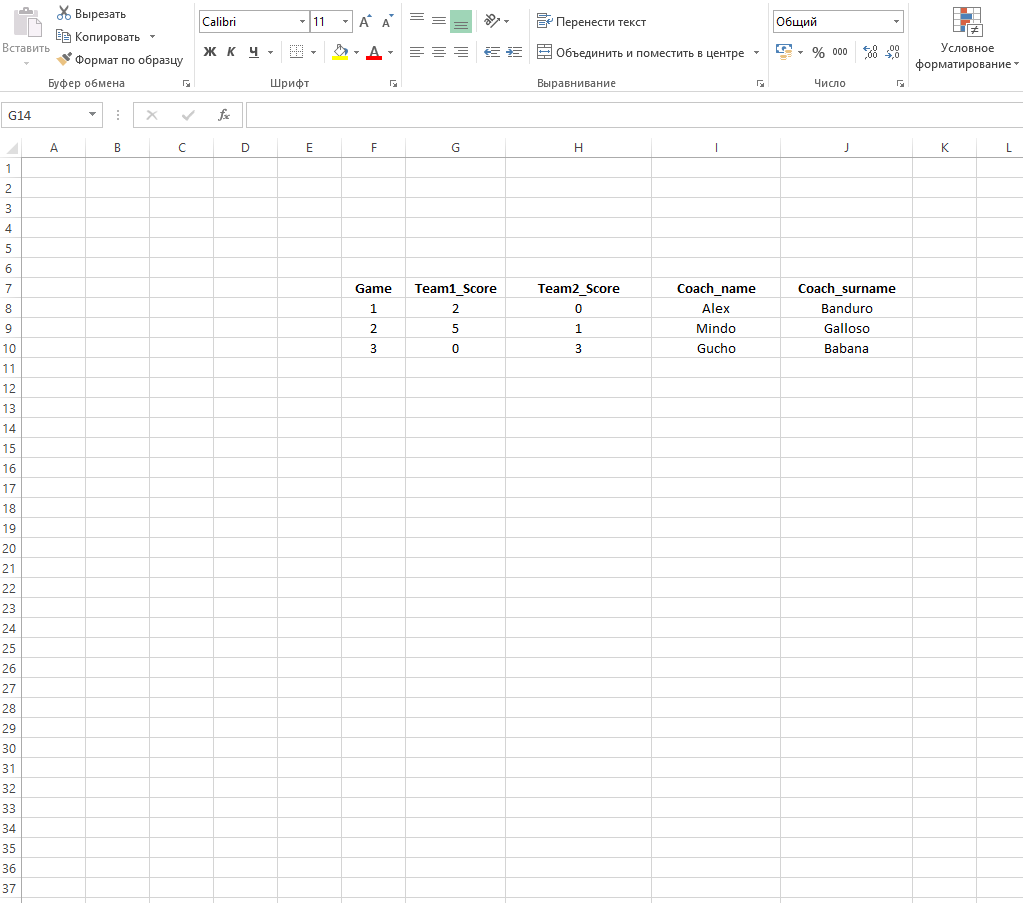
Нам очевидно, что с точки зрения удобства работы с базой практически все поля спроектированы неудачно: результат для каждой команды приведен в отдельном столбце, как и фамилия-имя тренера. Давайте это исправим с помощью всего пары строчек кода и функций пакета tidyr.
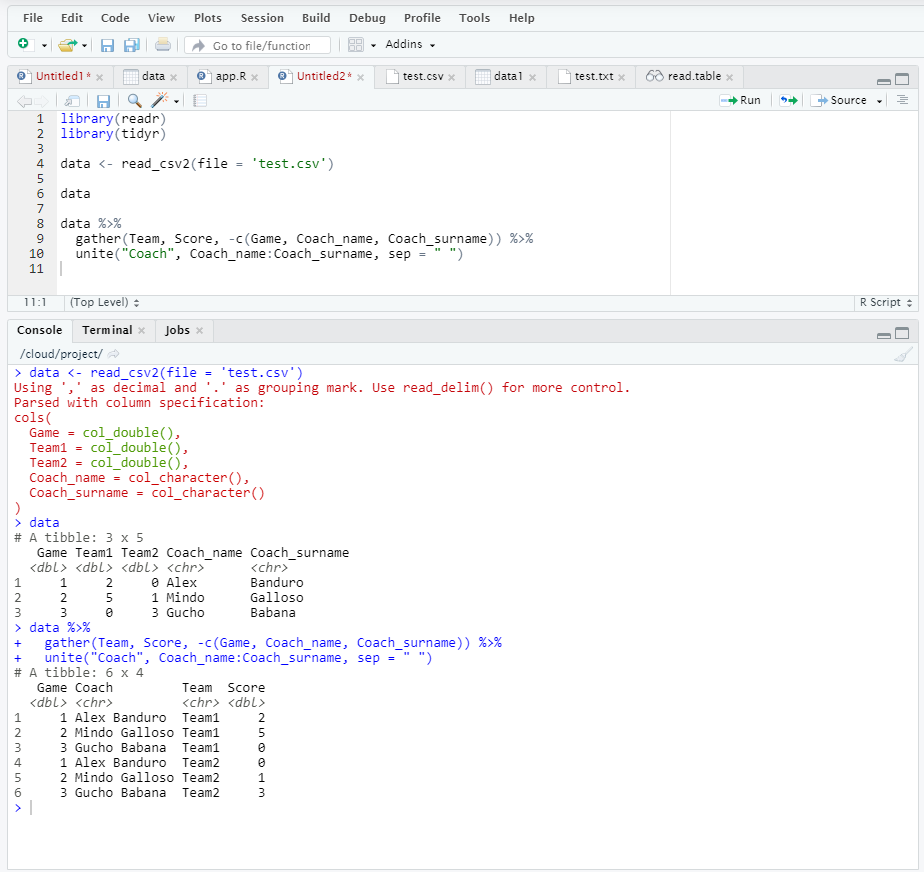
Мы загружаем исходную таблицу с помощью уже известного пакета readr. Выглядит таблица достаточно компактно, но с точки зрения концепции «аккуратных данных» или “tidy data” – это плохо спроектированная таблица.
Примечание. Tidy Data – основная концепция пакетов семейства tidyverse. Есть определенные законы и определения по поводу того, как должны выглядеть аккуратные данные. Если совсем тезисно – в каждой строке должно быть отдельное наблюдение, а в каждом столбце – отдельная величина. Если Вы внимательно посмотрите на наш набор данных, то увидите нарушение сразу обоих постулатов.
Итак, давайте немного приблизим нашу таблицу к требуемому виду. Используем две функции:
- gather для того, чтобы из множества однотипных столбцов сделать один с соответствующим столбцом значений. В нашем случае, столбцы Team1 и Team2, фактически, одинаковые – они показывают голы каждой команды в каждом матче. Соответственно, намного логичней сделать столбец-признак, где будет указано, о какой команде в данной строке идет речь, а также столбец-значение, где будет указано непосредственно количество голов данной команды в данном матче. Таким образом, у нас будет по 2 строки на каждый матч.
- unite для объединения фамилии и имени тренера – едва ли нам потребуются эти значения по-отдельности. А если потребуются – разделим.
На самом деле, таблицы бывают намного хуже и запущенней, в этой иллюстрации главным было показать удобство самой библиотеки tidyr – пару слов и все готово. Представьте, сколько времени Вы бы потратили в Excel.
Помимо рассмотренных функций, пакет tidyr предоставляет широкие возможности по ликвидации/заполнению пропусков; расширению таблиц; разбивке ячеек и много других полезных инструментов.
3. dplyr
Итак, данные получены и очищены – теперь можно переходить к обработке наконец? Да, теперь можно. И поможет нам в этом еще один пакет из экосистемы tidyverse – библиотека dplyr.
Как заявляется прям на официальном сайте, dplyr – грамматика обработки данных, которая содержит в себе все необходимые глаголы для комплексной обработки информации.
Давайте вместе с Вами повспоминаем все манипуляции, которые мы когда-либо делали с табличными данными. Вот мой список:
- Выделение подвыборок (например, выбор нескольких строк или столбцов по заданным условиям)
- Сортировка
- Добавление строк
- Добавление/изменение столбцов
- Группировка и расчет подытогов
- Комбинирование таблиц (различные джоины и юнионы)
Можно напрячься совсем сильно и вспомнить совсем какие-то незначительные вещи, но я Вас уверяю – каждую из задач, которые Вы придумаете, можно решить с помощью пакета dplyr. На мой взгляд, это просто алмаз индустрии обработки данных и must have любого аналитика или Data Scientistа. Да, я из тех, кто предпочитает tidyverse питоновскому Pandas. Ваш выбор остается за Вами, но Вы лишь посмотрите, как изящно и наглядно расправляется dplyr со своими задачами:

Мы загружаем стандартный датасет Ирис и всего в несколько строчек кода из большого датасета делаем маленькую табличку, совершив кучу преобразований:
- Сгруппировали по видам и рассчитали среднее значение каждой величины
- Отнормировали столбцы, в которых рассматривается длина. Ширину оставили без изменений.
- В итоговую таблицу выводим только столбцы с информацией о длине или о виде.
- Сортируем всю таблицу по столбцу с названием вида.
Написанный код выглядит более чем читаемо и понятно – не обязательно уметь программировать, можно в общих чертах понять смысл, даже если Вы просто владеете английским.
Эпилог
Мы с Вами рассмотрели всего 3 пакета из семейства tidyverse, но они точно пригодятся Вам в работе. Занимаетесь Вы аналитикой или автоматизацией процессов – не важно, рассмотренные библиотеки настолько фундаментальны, что без сомнения Вы с ними столкнетесь. А нас впереди ждет еще ни один рейтинг библиотек языка R, ведь интересных и полезных пакетов еще очень много!
Изучить язык R можно на курсе «Бизнес-аналитик» от SF Education!
Автор: Андрон Алексанян, эксперт SF Education

