
Пишем скоринговую модель на Python
 6 мин
6 мин
 8719
8719  24 Июл 2020
24 Июл 2020 
Основатель и Генеральный директор, SF Education


Кредитный скоринг – одна из наиболее распространенных задач среди множества проблем, решаемых финансовыми аналитиками. В данной статье мы разберемся с ключевыми шагами для написания собственной скоринговой модели на Python. Если вы только начали изучение Python, то рекомендуем записаться на наш открытый онлайн-курс «Первый код на Python».
Два наиболее важных вопроса кредитования:
- Насколько рискованно поступает заемщик, беря кредит?
- Учитывая известный риск заемщика, должны ли мы его кредитовать?
Определить рискованность действий заемщика можно опираясь на данные об экономическом поведении как его самого, так и результаты кредитования предыдущих заемщиков.
Для чего нужна скоринговая модель?
Вопрос, который максимально интересует банк в вопросе кредитования потребителей — это сможет ли он\она вернуть займ. Соответственно, все модели будут пытаться предугадать вероятность возврата( или дефолта) данного заемщика на основе имеющихся факторов и параметров: заработка, кредитной истории, уже имеющиеся кредиты.
В реальной жизни при построении данных моделей мы сталкиваемся с неполными данными, поэтому в данной статье мы сфокусируемся на двух моментах:
- Что делать, если часть данных отсутствует?
- Как строить классификаторы для несбалансированных выборок?
В качестве реальных данных воспользуемся выборкой из 9.5 тысяч записей с сайта LendingClub.com с мая 2007 года по февраль 2010 года. При этом стоить обратить максимальное внимание на тот факт, что на данный временный отрезок пришёлся пик кризиса, поэтому данные будут представлять собой так называемый «стрессовый сценарий». Поэтому для поведения заемщиков в некризисные периоды нам нужно будет найти другую выборку, скажем с 2013 по 2016 год, но при этом нам придется решать схожие проблемы с данными.
В качестве библиотек и функций импортируем следующие:
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from imblearn.pipeline import make_pipeline as imb_make_pipeline
from imblearn.under_sampling import RandomUnderSampler
from imblearn.ensemble import BalancedBaggingClassifier, EasyEnsemble
from sklearn.preprocessing import Imputer, RobustScaler, FunctionTransformer
from sklearn.ensemble import RandomForestClassifier, VotingClassifier, GradientBoostingClassifier
from sklearn.model_selection import train_test_split, cross_val_score, cross_val_predict
from sklearn.metrics import (roc_auc_score, confusion_matrix, accuracy_score, roc_curve,
precision_recall_curve, f1_score)
from sklearn.pipeline import make_pipeline
Знакомство с данными
Для начала ознакомимся с признаками, соответствующими столбцам датасета:
- credit_policy: значение показателя равно 1, если клиент отвечает критериям кредитного андеррайтинга LendingClub.com или 0 в противном случае.
- purpose: цель кредита (credit_card, debt_consolidation и т. д.).
- int_rate: процентная ставка по кредиту (в десятичных долях).
- installment: ежемесячные взносы заемщика.
- log_annual_inc: натуральный логарифм годового дохода заемщика.
- dti: отношение займа к доходу.
- fico: кредитная оценка заемщика по системе FICO.
- days_with_cr_line: число дней кредитной линии заемщика.
- revol_bal: возобновляемый баланс заемщика.
- revol_util: коэффициент использования возобновляемого баланса заемщика.
- inq_last_6mths: количество запросов заемщика кредиторам за последние 6 месяцев.
- delinq_2yrs: количество раз за последние два года, когда заемщик просрочил оплату более чем на 30 дней.
- pub_rec: количество негативных отметок в кредитной записи.
- not_fully_paid: 1 указывает, что долг не был выплачен полностью (заемщик обанкротился или маловероятно, что он вернет долг целиком). Этот признак и будет нашей целевой переменной.
Для начала определим тип данных каждого признака:
df = pd.read_csv("loans.csv")
print(df.dtypes)
В результате можно видеть, что единственным категориальным признаком является признак purpose:
credit_policy int64 purpose object int_rate float64 installment float64 log_annual_inc float64 dti float64 fico int64 days_with_cr_line float64 revol_bal int64 revol_util float64 inq_last_6mths float64 delinq_2yrs float64 pub_rec float64 not_fully_paid int64
Определим число пустых ячеек в каждом столбце:
print(df.isnull().sum())В таблице имеется небольшое число пропусков для шести признаков:
credit_policy 0 purpose 0 int_rate 0 installment 0 log_annual_inc 4 dti 0 fico 0 days_with_cr_line 29 revol_bal 0 revol_util 62 inq_last_6mths 29 delinq_2yrs 29 pub_rec 29 not_fully_paid 0
Рассмотрим как сбалансирована выборка относительно оплаченных кредитов:
pos = df[df["not_fully_paid"] == 1].shape[0] neg = df[df["not_fully_paid"] == 0].shape[0] plt.figure(figsize=(8, 6)) sns.countplot(df["not_fully_paid"]) plt.xticks((0, 1), ["Оплачено полностью", "Оплачено не полностью"]) plt.xlabel("") plt.ylabel("Число заемщиков")
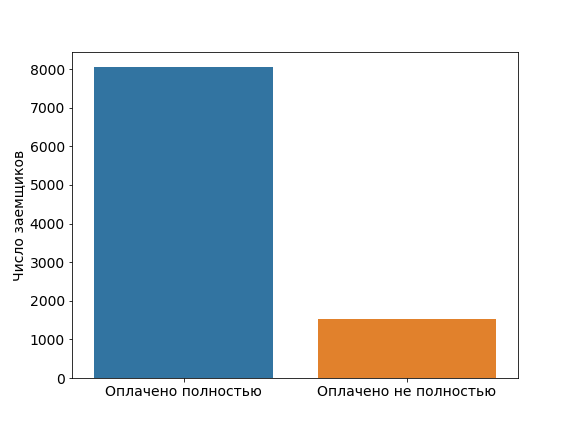
Полученная диаграмма показывает, что выборка не сбалансирована относительно целевой переменной not_fully_paid.
Начальные соображения и предобработка данных
Для моделирования будем применять алгоритмические композиции, представляющие собой объединения моделей в более сложную для уменьшения ошибок обобщения. Такой подход полагается на предположение, что каждая модель рассматривает различные аспекты данных, захватывая часть общей истинной картины. Сочетая независимо обученные модели, можно достичь лучших результатов, чем при использовании их одиночных экземпляров. Это приводит к более точным предсказаниям и меньшим ошибкам обобщения.
Производительность алгоритмических композиций почти всегда возрастает с ростом числа используемых моделей. Объединение максимально различных моделей уменьшает корреляцию между ними и повышает производительность композиции — коррелирующие между собой модели дают производительность идентичную или даже худшую, чем одиночная модель.
Кратко рассмотрим наиболее распространенные подходы к построению алгоритмических композиций:
- Смешивание (blending, блендинг): усреднение прогнозов группы моделей.
- Бэггинг (баггинг, bagging, bootstrap aggregating): независимое построение моделей на различных наборах данных с последующим выбором предсказания по результатам голосования моделей.
- Бустинг (boosting): последовательное построение моделей, при котором каждая модель учится с учетом результатов предыдущей модели. Чтобы избежать ошибок переобучения, каждая новая модель учится на результатах всех предыдущих моделей.
- Стекинг (stacking): построение k моделей базовых учеников с дальнейшей подгонкой модели под метаклассификатор.
В нашей модели мы будем использовать бэггинговую модель случайного леса (Random Forest). Обратим внимание, что далее в коде мы проведем предварительную обработку данных:
- Создадим переменные признака purpose вместо используемых категориальных значений.
- Разобьем данные на обучающую (80%) и тестовую (20%) выборки.
- Чтобы выбросы в данных оказывали меньшее влияние на обучение, стандартизируем выборку при помощи метода RobustScaler.
Этот метод центрует данные вокруг медианы и масштабирует их с использованием межквартильного диапазона.
Стратегии работы с пропущенными значениями
В реальных выборках встречаются пропуски данных. Это может быть вызвано тем, что клиенты не заполнили часть банковских форм, изменились сами формы и т. д.
Одна из хороших практик учета отсутствующих данных — генерация бинарных функций. Такие функции принимают значение 0 или 1, указывающие на то, присутствует ли в записи значение признака или оно пропущено.
Другими распространенными практиками являются следующие подходы:
- Удаление записей с отсутствующими значениями. Обычно так делается, если число недостающих значений очень мало в сравнении со всей выборкой, при этом сам факт пропуска значения имеет случайный характер. Недостатком такой стратегии является возникновение ошибок в случаях идентичных пропусков в тестовых данных.
- Подстановка среднего, медианного или наиболее распространенного значения данного признака.
- Использование различных предсказательных моделей для прогнозирования пропущенного значения при помощи остальных данных датасета.
Начнем с создания бинарных функций для отсутствующих значений, а затем вычислим показатель AUC для различных моделей на обучающей выборке:
df = pd.get_dummies(df, columns=["purpose"], drop_first=True) for feature in df.columns: if np.any(np.isnan(df[feature])): df["is_" + feature + "_missing"] = np.isnan(df[feature]) * 1
Выделим в качестве целевой переменной признак not_fully_paid и разобьем данные на обучающую и тестовую выборки:
X = df.loc[:, df.columns != "not_fully_paid"].values y = df.loc[:, df.columns == "not_fully_paid"].values.flatten() X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=0, stratify=y) print("Оригинальные размеры данных: ", X_train.shape, X_test.shape)
В результате получаем:
Оригинальные размеры данных: (7662, 24) (1916, 24)
Рассмотрим в нашем примере самый простой вариант – выкинем из выборки записи с пропусками:
train_indices_na = np.max(np.isnan(X_train), axis=1) test_indices_na = np.max(np.isnan(X_test), axis=1) X_train_dropna, y_train_dropna = X_train[~train_indices_na, :][:, :-6], y_train[~train_indices_na] X_test_dropna, y_test_dropna = X_test[~test_indices_na, :][:, :-6], y_test[~test_indices_na] print("После выкидывания NA: ", X_train_dropna.shape, X_test_dropna.shape)
В результате запуска увидим:
После выкидывания NA: (7610, 18) (1906, 18)
Построим классификатор случайного леса и определим показатель AUC для данной модели:
rf_clf = RandomForestClassifier(n_estimators=500, max_features=0.25, criterion="entropy", class_weight="balanced") pip_baseline = make_pipeline(RobustScaler(), rf_clf) scores = cross_val_score(pip_baseline, X_train_dropna, y_train_dropna, scoring="roc_auc", cv=10) print("Среднее значение AUC базовой модели {}".format(scores.mean()))
Запуск кода дает:
Среднее значение AUC базовой модели 0.662.
Проверим, улучшают ли бинарные функции качество нашей модели:
rf_clf.fit(RobustScaler().fit_transform(Imputer(strategy="median").fit_transform(X_train)), y_train) importances = rf_clf.feature_importances_ indices = np.argsort(rf_clf.feature_importances_)[::-1] plt.figure(figsize=(12, 6)) plt.bar(range(1, 25), importances[indices], align="center") plt.xticks(range(1, 25), df.columns[df.columns != "not_fully_paid"][indices], rotation=90) plt.title("Значимость признаков")
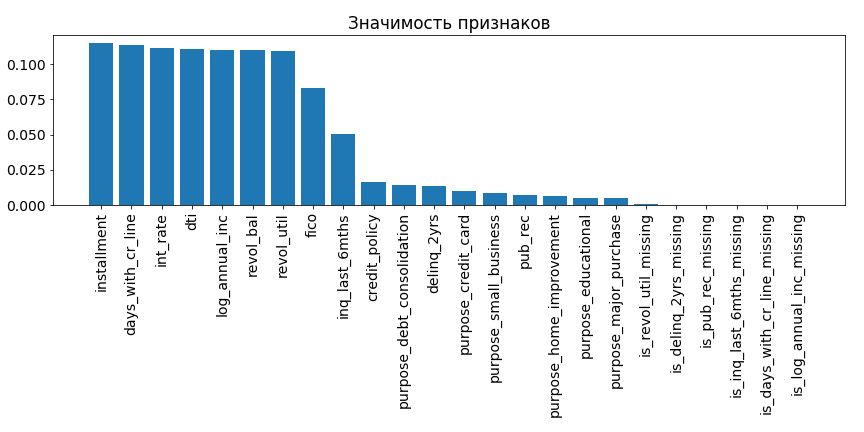
Вы можете попробовать и более сложные стратегии, однако для такого малого числа потерь данных при использовании различных подходов обработки пропусков обычно наблюдаются сопоставимые результаты. Рассматривая полученную диаграмму, можно заметить, что добавление двоичных функций в этом конкретном случае не приводит к приросту производительности модели. Таким образом для нашей выборки их можно удалить:
X_train = X_train[:, :-6] X_test = X_test[:, :-6]
Стратегии работы с несбалансированными выборками
Лучшими метриками для несбалансированных наборов данных считаются AUC (площадь под ROC-кривой) и f1-score. Но одних метрик недостаточно — классовый дисбаланс влияет на процесс обучения модели, делая ее предвзятой. В этом случае используются следующие подходы:
- Удалить часть экземпляров мажоритарного класса так, чтобы сравнять число положительных и отрицательных примеров (недостаток: существенная потеря данных.
- Дополнить повторами миноритарные представители класса, чтобы сравнять число положительных и отрицательных примеров (недостаток: возможное переобучение на повторяющихся примерах).
- Избирательно настроить классификатор на объекты мажоритарного/миноритарного классов.
- Создать синтетические объекты миноритарного класса.
В большинстве приложений неправильная классификация меньшинства (ложноотрицательная классификация) стоит намного дороже ложноположительной. В контексте кредитования потеря денег из-за незаслуживающего доверия заемщика обходится существенно выше, чем отсутствие возможности кредитования надежного заемщика. Поэтому мы можем назначать этим классам различные веса и отсечки.
В качестве примера сравним результат прошлой модели случайного леса с теми, где мы либо сбалансируем выборку, удалив часть мажоритарных записей (under-sample подход), либо воспользуемся синтетическим подходом:
rf_clf = RandomForestClassifier(n_estimators=500, max_features=0.25, criterion="entropy", class_weight="balanced") pip_orig = make_pipeline(Imputer(strategy="mean"), RobustScaler(), rf_clf) scores = cross_val_score(pip_orig, X_train, y_train, scoring="roc_auc", cv=10) print("AUC оригинальной модели: ", scores.mean()) pip_undersample = imb_make_pipeline(Imputer(strategy="mean"), RobustScaler(), RandomUnderSampler(), rf_clf) scores = cross_val_score(pip_undersample, X_train, y_train, scoring="roc_auc", cv=10) print("AUC модели без большей части мажоритарных примеров: ", scores.mean()) resampled_rf = BalancedBaggingClassifier(base_estimator=rf_clf, n_estimators=10, random_state=0) pip_resampled = make_pipeline(Imputer(strategy="mean"), RobustScaler(), resampled_rf) scores = cross_val_score(pip_resampled, X_train, y_train, scoring="roc_auc", cv=10) print("AUC модели EasyEnsemble: ", scores.mean())
Результат работы скрипта:
AUC оригинальной модели: 0.663 AUC модели без большей части мажоритарных примеров: 0.658 AUC модели EasyEnsemble 0.671
Можно видеть, что в случае рассматриваемой выборки простое исключение экземпляров мажоритарного класса не приводит к улучшению качества предсказания модели. В то же время применение синтетического подхода, например, EasyEnsemble, позволяют сбалансировать выборку и улучшить предсказательные возможности модели.
Такие сбалансированные классификаторы можно обучать и делать на них предсказания аналогично традиционным:
resampled_rf.fit(X_train_dropna, y_train_dropna) print(y_test_dropna[-3], y_test_dropna[-2]) print(resampled_rf.predict([X_test_dropna[-3]]), resampled_rf.predict([X_test_dropna[-2]]))
Вывод:
1 0 [1] [0]
Для улучшения предсказания скоринговых моделей существует гораздо больше сложных концепций, чем мы можем изложить в рамках одной публикации. С некоторыми из них в продолжение работы с этой статьей на примере того же датасета вы можете ознакомиться здесь.

