
Модель Монте-Карло в Python
 7 мин
7 мин
 8647
8647  13 Май 2020
13 Май 2020 
Основатель и Генеральный директор, SF Education


В сегодняшней статье мы рассмотрим, как создать упрощённую модель по методу Монте-Карло, используя Python, а не плагин @RISK для Excel.
Методы Монте-Карло полагаются на случайную выборку для получения численных результатов. Одним из них является получение случайных выборок из распределения вероятностей, представляющих неопределенные потенциальные будущие состояния популяции, где переменные могут принимать различные значения.
Наглядно рассмотрение моделирования Монте-Карло на упрощенной модели DCF вместо более сложных примеров оценки опционов или других производных инструментов, так как для этого нам понадобится только финансовый отчет и модель дисконтирования денежных потоков, позволит сосредоточиться на логике и инструментах Python. Еще больше об инструментах Python можно узнать на нашем открытом онлайн-курсе «Первый код на Python».
Обратите внимание, что эта базовая учебная модель предназначена для иллюстрации ключевых понятий и не является полезной как таковой для каких-либо практических целей.
Отправная точка и желаемый результат
В нашей простой модели Монте-Карло содержатся ключевые позиции из финансовой отчетности и три выделенные ячейки с входящими данными, имеющие точные оценки в Excel, которые мы теперь хотим заменить вероятностными распределениями, чтобы начать изучать потенциальные диапазоны результатов.
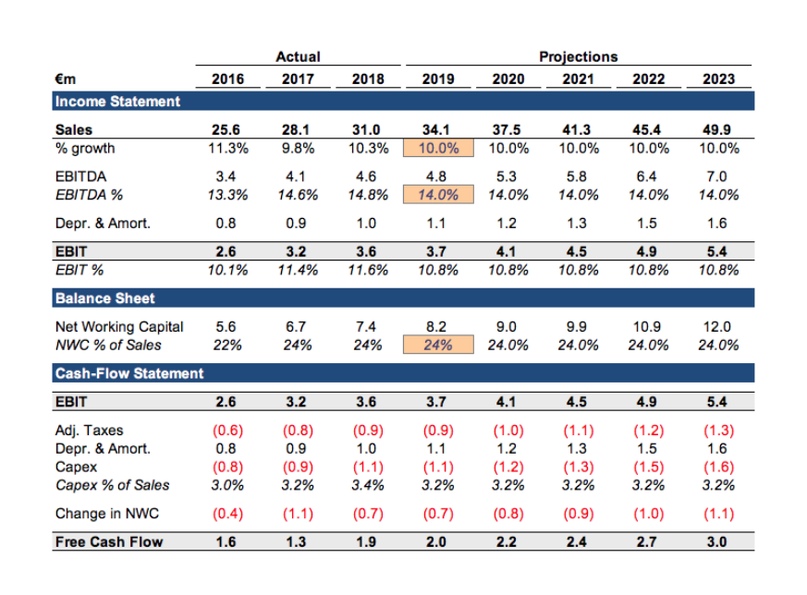
Двухэтапный подход к разработке скрипта
Цель кейса – дать специалистам по финансам введение не только в программу, но и в итерационный процесс, который можно применить для ее разработки.
1. Разработка рабочего прототипа с нуля;
2. Разработав рабочий прототип, можно воспользоваться преимуществом рефакторинга — изменение структуры кода без изменения его функциональности. Это красивое решение, и, как бонус, оно примерно в 75 раз быстрее.
Разработка рабочего прототипа
1 шаг. Настройка Jupyter Notebook
Jupyter notebook — это отличный инструмент для работы с Python в интерактивном режиме. Это интерактивный интерпретатор Python с ячейками, которые могут содержать код, текст Markdown, изображения или другие данные. Для этого кейса использовалась платформа Python Quant, однако также удобна Colaboratory от Google (бесплатно и работает в облаке). После запуска выберите “New Python 3 Notebook ” в меню “File”.
2 шаг. Импортировать внешние пакеты, необходимые для обработки данных и визуализации, и сообщить программе, что мы хотим видеть диаграммы в нашей оболочке, а не в отдельных окнах:

Важное уточнение, прежде чем мы начнем перечислять первые переменные. Читабельность является одной из сильных сторон Python. Языковой дизайн проходит долгий путь, чтобы добиться этого, но каждый, кто пишет код, несет ответственность за то, чтобы сделать его читаемым и понятным не только для других, но и для себя.
Как гласит закон Иглсона: «любой ваш собственный код, который вы не рассматривали в течение шести или более месяцев, мог быть написан кем-то другим».
Хорошее эмпирическое правило состоит в том, чтобы назвать компоненты программы таким образом, чтобы свести к минимуму необходимость в отдельных комментариях, которые объясняют, что они делают.
Имея это в виду, давайте двигаться дальше.
Создание отчета
Есть много способов, при помощи которых мы можем работать с данными электронных таблиц в Python. Мы могли бы, например, прочитать лист в Pandas DataFrame с однострочным кодом, используя команду read_excel. Если вы хотите более тесную интеграцию и связь в реальном времени между электронной таблицей и Python, есть и бесплатные варианты для обеспечения этой функциональности.
Поскольку наша модель очень проста, чтобы сосредоточиться на концепциях Python, мы будем воссоздавать ее с нуля в нашем скрипте. Также вы увидите, как наладить экспорт в электронную таблицу.
1 шаг. Выбор подходящей структуры данных.
Выбор велик: есть встроенные в Python, можно воспользоваться многочисленными библиотеками или создать собственную. А пока давайте воспользуемся Series из библиотеки Pandas:

Входящие и соответствующие выходные данные:
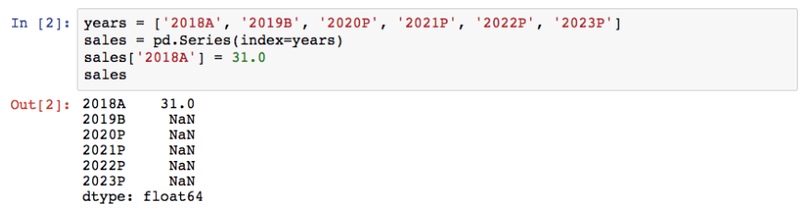
С помощью первых трех строк мы создали структуру данных с индексом, состоящим из периодов (каждый имеет свой маркер: факт, бюджет или прогноз), начального значения (в миллионах евро, как в исходной модели DCF) и пустых (NaN, «not a number») – для прогнозов.
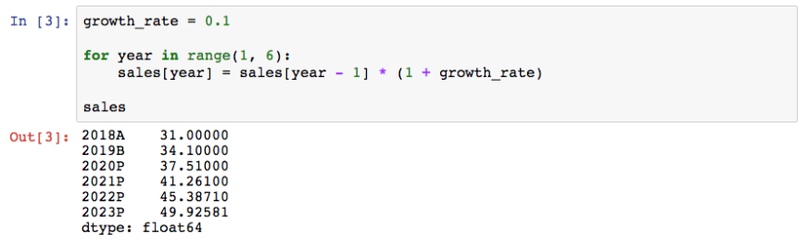
2 шаг. Установка дефлятора для прогнозируемого годового роста продаж.
На данном этапе это будет точная оценка, цифра, как и в нашей оригинальной модели DCF. Сначала используем те же самые входные данные для подтверждения, что наша версия Python дает тот же результат, что и версия Excel, прежде чем рассматривать замену точных оценок распределениями вероятностей. Используя эту переменную, мы создаем цикл, который вычисляет продажи в каждом прогнозном году на основе предыдущего года и темпов роста:

Теперь у нас есть прогнозируемые продажи, а не NaN:
Используя тот же подход, мы продолжаем, чтобы в конечном итоге получить свободный денежный поток.
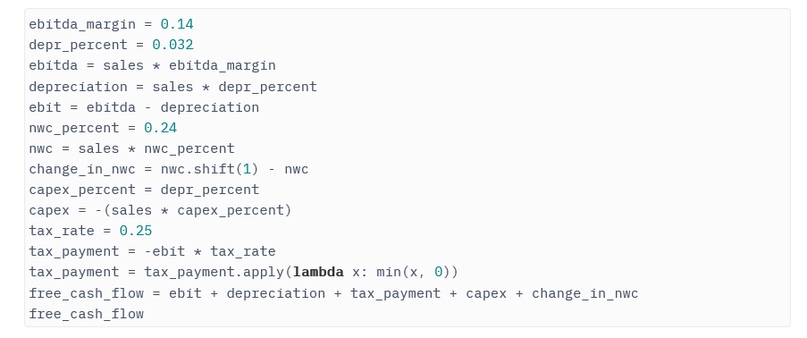
В итоге получаем расчет свободного денежного потока:
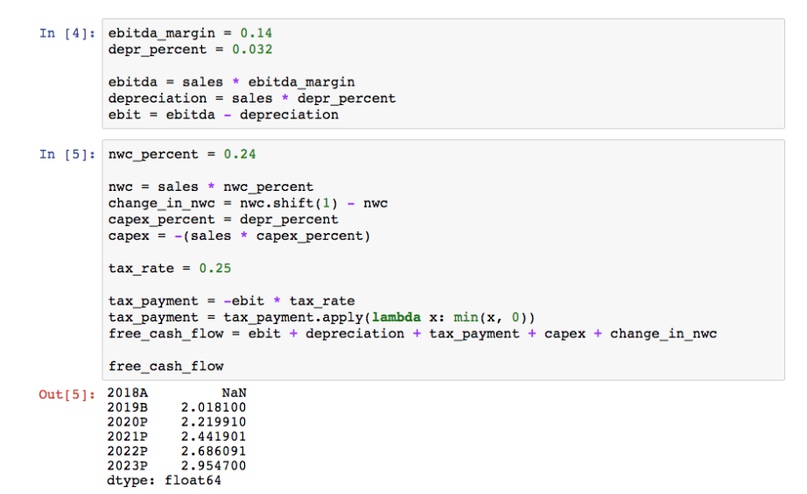
Одна строка, которая, нуждается в комментарии – это tax_payment. Здесь применена функция, чтобы избежать положительного налогового платежа в сценариях, где прибыль до налогообложения становится отрицательной. Это лишний раз демонстрирует, насколько эффективно можно применять пользовательские функции ко всем ячейкам в Pandas Series или DataFrame.
Более реалистичная модель скорее всего потребует отдельную налоговую модель, которая вычисляет фактические денежные налоги, уплаченные на основе ряда специфических для компании факторов.
Выполнение оценки DCF
Теперь мы можем рассчитать терминальную стоимость и дисконтировать денежные потоки, чтобы получить результат DCF. Следующий код позволяет обеспечить один или несколько элементов в структуре данных на примере Pandas Series.
Квадратные скобки после названия показателя приведет к простой индексации, начиная с нуля, что означает, что free_cash_flow[1] вернет нам второе значение. [-1] апеллирует к последнему значению денежного потока за последний год (используется для вычисления терминальной стоимости), а использование двоеточия [1:] включает в расчет все элементы, кроме первого, поскольку мы не должны включать исторический год 2018A в оценку DCF.
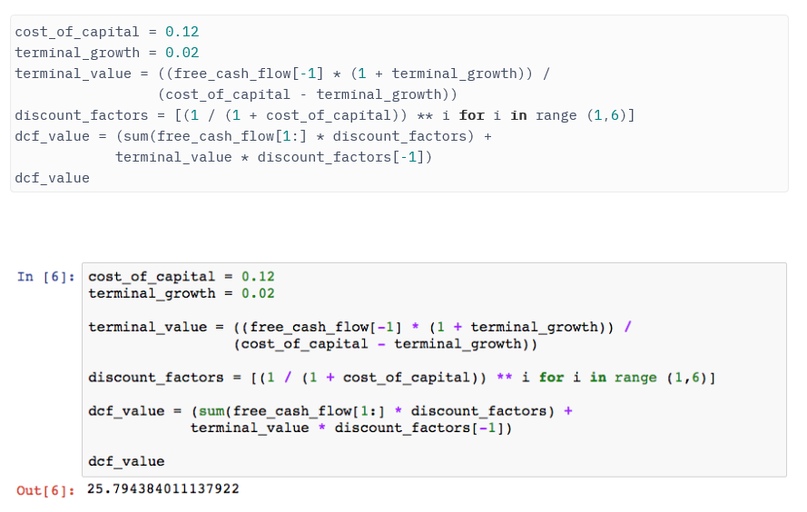
Это завершает первую часть нашего кейса: теперь у нас есть хотя и рудиментарная, но рабочая модель DCF в Python.
Экспорт данных
Прежде чем перейти к моделированию Монте-Карло, необходимо упомянуть о возможностях экспорта, доступных в пакете Pandas: объект DataFrame библиотеки Pandas вы можете записать в файл Excel, используя метод to_excel. Однако существует аналогичная функциональность для экспорта в более, чем дюжину других форматов.
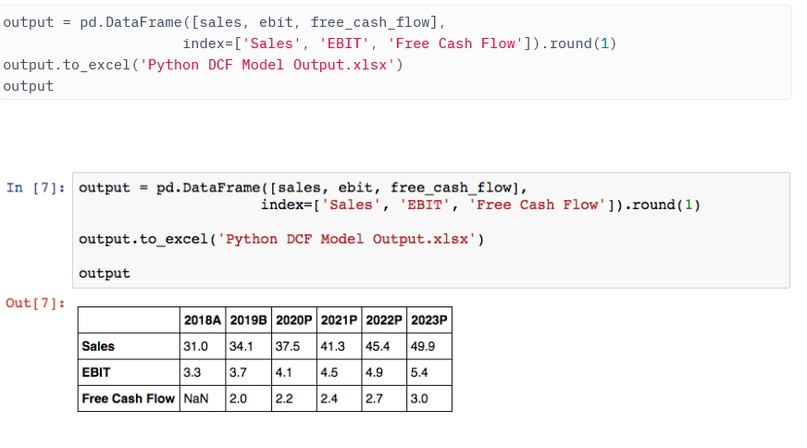
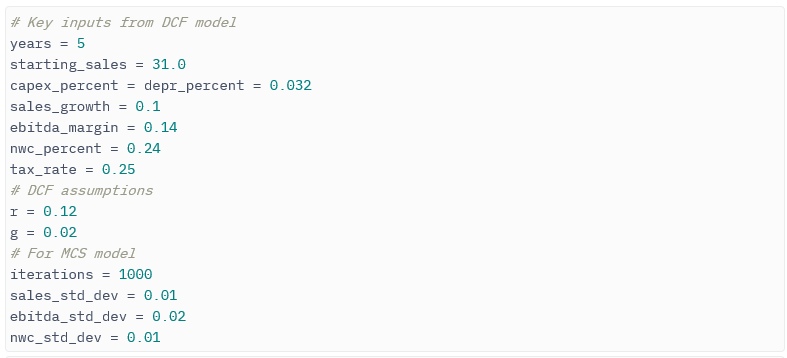
Создание вероятностных распределений для моделирования Монте-Карло
Решим следующую задачу: заменим некоторые из точных значений вероятностными распределениями. Предыдущие шаги могли показаться несколько громоздкими по сравнению с построением той же модели в Excel, однако следующий этап несомненно продемонстрирует мощный функционал Python.
1 шаг. Определяем количество итераций, например, 1000.
Это обеспечит баланс между достаточным объемом данных и разумным сроком для завершения моделирования.
2 шаг. Генерируем фактические распределения.
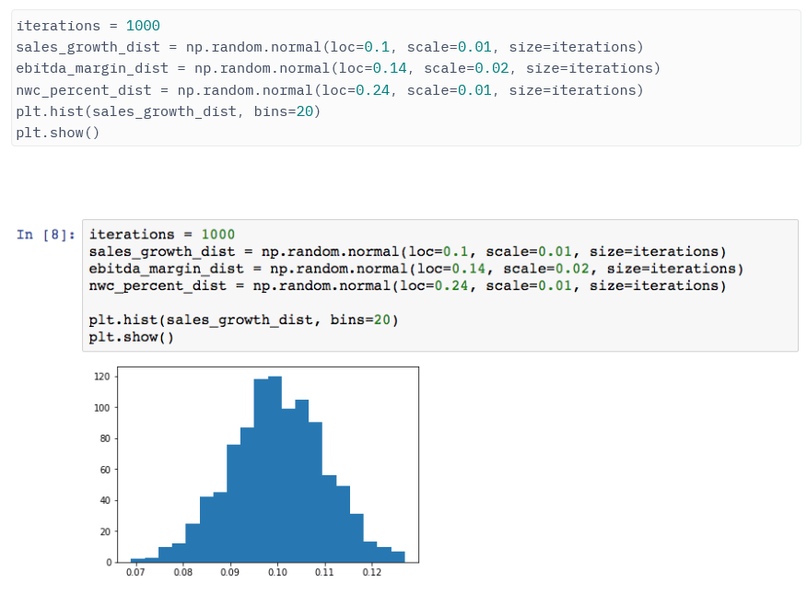
Для упрощения создаем три нормальных распределения, однако библиотека NumPy поддерживает большее количество (есть и другие опции, включая стандартную библиотеку Python).
После принятия решения о том, какое распределение использовать, нам нужно указать параметры, необходимые для описания их формы, такие как среднее и стандартное отклонение, а также количество желаемых результатов.
Очевидно, что EBITDA имеет корреляцию с показателем продаж. Более того, она зависит от динамики структуры затрат (переменные, полупеременные и постоянные затраты) и ключевых факторов затрат (некоторые из которых могут иметь свои собственные распределения вероятностей, такие как, например, цены на сырьевые товары), но для упрощения оставим это за пределами нашего сценария.
Чем меньше данных для выбора распределения и параметров, тем больше придется полагаться на результаты различных рабочих потоков, чтобы сформировать консенсусный диапазон сценариев.
В примере с прогнозами денежных потоков будет присутствовать большая субъективная составляющая, что означает, что визуализация вероятностных распределений становится важна. Получаем базовую визуализацию, показывающую распределение роста продаж, только с двумя короткими строками кода.
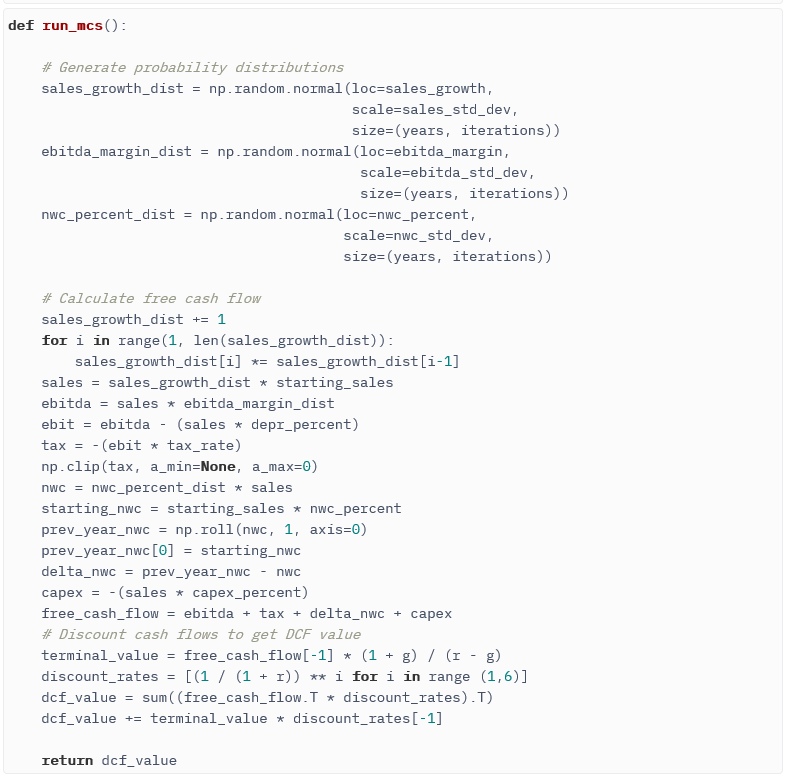
Теперь у нас есть все составляющие, необходимые для запуска моделирования, но они все еще в неподходящем формате. Вот тот же код, с которым мы работали до сих пор, но собран в одну ячейку и перестроен в функцию для удобства:

Теперь мы можем запустить весь процесс и построить распределение результата, которое будет представлять собой дисконтированную величину денежного потока этой компании в каждой из 1000 итераций, со следующим кодом. Команда %time – это быстрая команда для измерения времени выполнения (вместо этого можно использовать функцию Python из стандартной библиотеки).
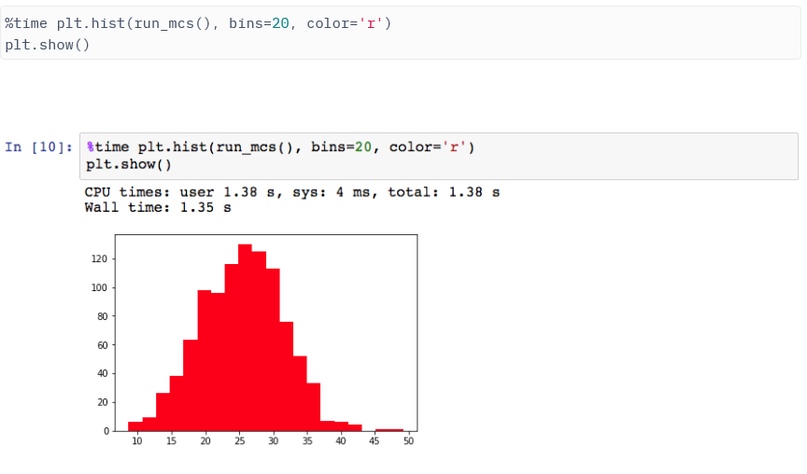
Доработка прототипа
Рефакторинг – процесс переписывания существующего кода для улучшения его структуры без изменения его функциональности, и это может быть одним из самых интересных и полезных элементов кодирования.
Как правило, используется для следующих функций:
1. Обработка различных частей более контекстным подходящим способом;
2. Переименование переменных и функций, чтобы сделать их назначение и работу более понятными;
3. Подготовка к будущим функциям (обеспечение возможности добавления нового функционала в существующее ПО);
4. Увеличение скорости выполнения, объема памяти или другого ресурса.
Прототип, который мы только что создали, собрав все начальные переменные в одном месте, изначально разрозненные в базовом сценарии прототипа, наглядно очищен, а также оптимизирована скорость его выполнения с помощью процесса, называемого векторизацией.
Теперь он выглядит прозрачнее для понимания:
Основное различие между текущей и предыдущей версией – это отсутствие цикла for i in range(iterations). Использование NumPy требует 18 миллисекунд, что примерно в 75 раз быстрее по сравнению с 1,35 секундами базового прототипа.
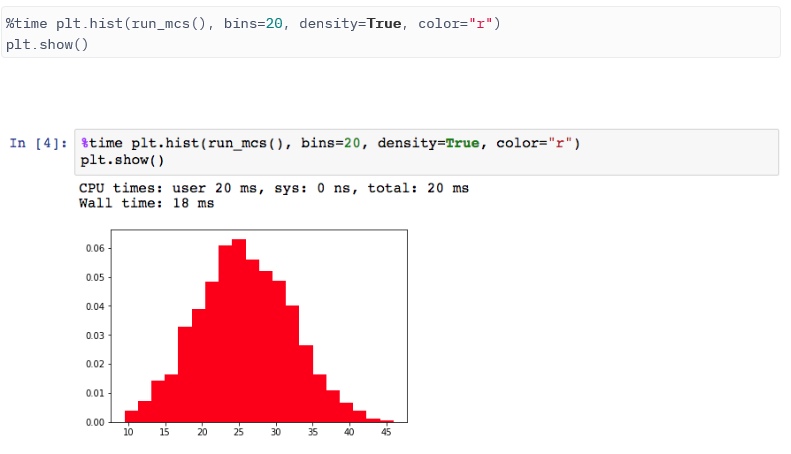
Возможна и дальнейшая оптимизация алгоритма.
Дальнейшие шаги
Этот пример показал некоторые из функций Python, и если вы загляните дальше, то увидите, что возможности почти бесконечны. Еще больше о функциях Python можно узнать в бесплатном гайде.
При дальнейшей разработке можно:
- загрузить статистику компании или сегмента с веб-страниц или других источников данных, чтобы обеспечить выбор предпосылок и распределения вероятностей;
- использовать Python в финансовых приложениях, таких как автоматизированный торговый робот, основанный на фундаментальных макроэкономических факторах;
- внедрить возможности экспорта в электронную таблицу или в формат презентации, которые будут использоваться как часть внутреннего процесса рассмотрения и согласования транзакций, а также для презентаций;
- создать веб-приложения, приложения для обработки данных и машинного обучения, которые и составляют успех Python.
Источник: Toptal


