
Чем полезен SQL для бизнеса и финансов
 9 мин
9 мин
 2118
2118  16 Авг 2021
16 Авг 2021 
Основатель и Генеральный директор, SF Education
Получите 3-х дневный бесплатный демо-период
SQL (или Structured Query Language) используют для работы с реляционными базами данных.
Рекомендуем скачать наш бесплатный гайд «Первые шаги в SQL», если вы хотите узнать о SQL больше.
Первая версия языка SQL была презентована еще в 1970-х. Изначально его создавали для конечных пользователей: бухгалтеров, финансистов, кладовщиков и других специалистов, которым нужно извлекать некие данные из общего массива. Более поздние версии SQL стали сложнее и превратились уже в инструмент разработки.
Более углубленно SQL, а также программирование на VBA и Python разбираем на нашем фундаментальном курсе «Бизнес-аналитик».
Как устроены реляционные базы данных и как работает SQL
Информация в реляционной базе данных хранится в таблицах. При этом таблицы должны соответствовать нескольким правилам:
- Данные в каждой строке соответствуют одному объекту и описывают его атрибуты. Например, каждая строка в таблице — это какой-то товар, и в столбцах указаны его название, цена, масса и пр. У атрибутов (столбцов) есть свои названия (они уникальны) и указан тип данных, которые в них хранятся.
- В таблице не может быть одинаковых строк. Поэтому вводят отдельное поле с уникальным номером или другим идентификатором. Его называют Primary Key (первичный ключ). Например, номер товар в базе данных: даже если будет совпадать название, масса и другие характеристики, строки можно будет однозначно идентифицировать по номеру.
- Друг с другом таблицы связаны с помощью Foreign Key (внешний ключ). Об этом чуть позже.
Посмотрим структуру таблицы в базе данных (БД) на примере таблицы товаров.
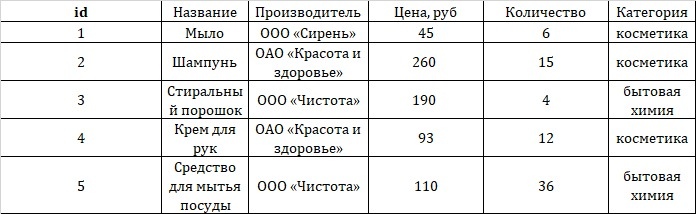
В качестве атрибутов выступают столбцы «id», «Название», «Производитель», «Цена», «Категория». В строках находятся данные, относящиеся к определенному товару.
В качестве уникального идентификатора выступает id. Он же может быть и внешним ключом для других таблиц. То есть, если нам надо выбрать из этой таблицы данные по конкретному товару, достаточно указать его id.
Также есть программы, которые называют системами управления реляционными базами данных (РСУБД). Когда вы пишите запрос в базу данных, СУБД его обрабатывает и выдает запрошенный результат. Как она это делает — пользователь обычно не знает, ему надо лишь уметь писать запросы.
Как раз это и делают на SQL. Пишут запрос по определенным правилам, в нем указывают, какие данные нужны. Например, все товары дороже 200 рублей из такой-то категории, которых не осталось на складе.
С помощью SQL можно создавать БД, добавлять, обновлять и удалять данные, извлекать различные наборы данных для их последующего использования, например, в аналитике.
А вот разработчикам, которые используют БД в своих приложениях, нужно иметь представление о том, как работает каждая СУБД — как она анализирует каждый оператор в запросе и создает план его выполнения.
SQL в Data Science
Бизнесу нужно обрабатывать большие объемы данных: строить прогнозы, выявлять тренды, анализировать потребности своих клиентов и их поведение — и в конечном итоге увеличивать прибыль. Поэтому требование знать SQL встречается во многих вакансиях Data Scientists и аналитиков в целом.
Для более мощного и гибкого анализа баз данных используют несколько разноплановых языков, например Python, R и SQL.
Теперь познакомимся с основами SQL — он пригодится и финансистам, и бухгалтерам, и бизнес-аналитикам, и Data Scientist`ам.

Основные операторы языка SQL
Существует много систем управления базами данных (СУБД): Oracle Database, Interbase, Firebird, Microsoft SQL Server, PostgreSQL и другие. В каждой применяется язык SQL, но с некоторыми модификациями.
Разница может быть в синтаксисе или обработке запросов, но общая канва схожа, так что освоить конкретные вариации (например PL/SQL, PSQL, PL/pgSQL) будет несложно.
Мы познакомимся с SQL, который применяется в PostgreSQL. Это мощная система объектно-реляционных баз данных с открытым исходным кодом. Для работы в ней используется терминал psql — программа, в которую вы вводите запросы и видите результаты их обработки.
На этапе обучения языку в первую очередь вам понадобятся команды, которые описывают свойства таблиц и баз данных, функции языка и другую справочную информацию. Все они начинаются с обратного слеша (\).
Чаще всего используются следующие команды:
\h [команда] Справка по SQL: список доступных команд или синтаксис конкретной команды; \с [имя БД] Подключение к базе данных; \l Показать список баз данных; \dt Показать список таблиц; \d [имя] Показать подробную информацию по конкретному объекту (например, таблице или индексу); \q Выход из psql;Создание базы данных
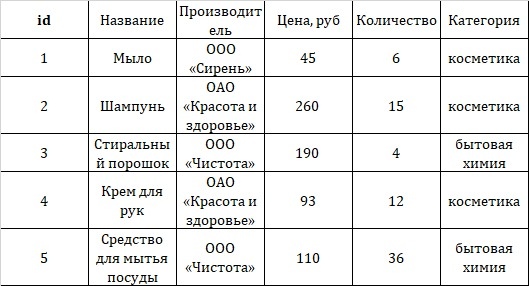
Теперь перейдем к созданию базы данных. В ней будут две таблицы:
Goods
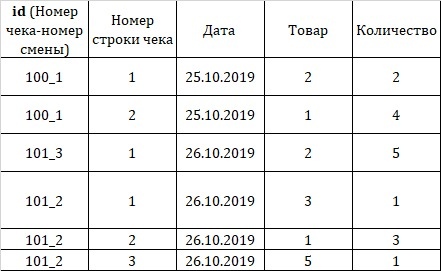
Bill
Для создания БД используют оператор CREATE DATABASE [имя_базы]. Мы создадим базу данных, которая будет называться, например, «Shop».
Команды языка SQL заканчиваются точкой с запятой — (;). Без этого знака команда не будет обработана.
CREATE DATABASE Shop;После ввода команды система вам ответит.

Мы создали нашу базу данных. Теперь команда \l выдаст нам обновленный список баз данных, хранящихся на сервере.
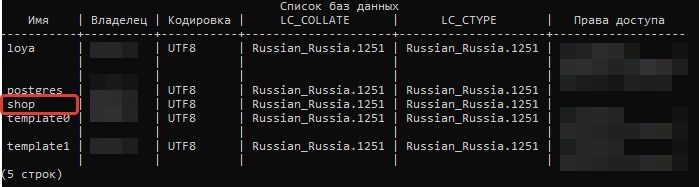
Теперь нужно подключиться к этой базе данных. Используем команду \сonnect.
\connect shop
Все, теперь мы можем работать с базой.
Создание таблиц с данными
Для этого нужно перечислить все атрибуты (названия столбцов), типы данных, хранящихся в этих столбцах, указать Primary Key.
CREATE TABLE goods( id integer PRIMARY KEY, name text, maker text, price float4, quantity integer, category text);Мы создали первую таблицу, указав в качестве Primary Key — id товара. Теперь заполним таблицу. Это действие выполняет команда INSERT INTO.
INSERT INTO goods VALUES (001, ‘Мыло’, ‘ООО «Сирень» ‘, 45, 6, ‘косметика’), (002, ‘Шампунь’, ‘ОАО «Красота и здоровье» ‘, 260, 15, ‘косметика’), (003, ‘Порошок’, ‘ООО «Чистота» ‘, 190, 4, ‘бытовая химия’), (004, ‘Крем для рук’, ‘ОАО «Красота и здоровье» ‘, 93, 12, ‘косметика’), (005, ‘Средство для мытья посуды’, ‘ ООО «Чистота» ‘, 110, 36, ‘бытовая химия’);Теперь в нашей таблице пять строк. Чтобы проверить, что находится в таблице «goods», можем воспользоваться командой SELECT:
SELECT * FROM goods;
Это запрос, который выводит всё (значок *) из таблицы «goods».
Чтобы выбрать какие-то определенные атрибуты из таблицы, вместо * в скобочках нужно указать названия столбцов. Например, выведем на экран только название и стоимость товаров:
SELECT name, price FROM goods;
Знание английского даже на самом начальном уровне сильно облегчает понимание языка запросов.
Более сложные запросы мы рассмотрим далее. А пока аналогично создадим вторую таблицу:
CREATE TABLE bill( id text, num_string integer, date date, goods integer REFERENCES goods(id), quantity integer);Эта таблица связана с таблицей «goods» по внешнему ключу — id. Чтобы указать на Foreign Key, нужно применить оператор REFERENCES (ссылки) и написать название таблицы, а в скобках — атрибут, по которому таблицы связаны.
Добавим строки в таблицу «bill»:
INSERT INTO bill VALUES (‘100/1’, 1, ‘2019-10-25’,002,2), (‘100/1’, 2, ‘2019-10-25’,001,5), (‘101/3’, 1, ‘2019-10-26’,002 ,4), (‘101/2’, 1, ‘2019-10-26’, 003, 1), (‘101/2’, 2, ‘2019-10-26’, 001, 3), (‘101/2’, 3, ‘2019-10-26’, 005, 1);Дата в SQL указывается в обратном порядке: ‘гггг-мм-дд’ (в одинарных кавычках).
Все, подготовительные действия закончились. Мы создали и заполнили таблицы. Теперь потренируемся делать запросы.
Простые запросы на языке SQL
Самый простой способ мы уже знаем:
SELECT * FROM [название таблицы].Но очень редко специалисту нужно выводить всю таблицу. Для более узкого запроса есть полезный оператор — WHERE. Он накладывает ограничения на выводимые значения.
Например,
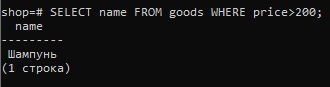
SELECT name FROM goods WHERE price>200;Результатом запроса будет одна строка: «Шампунь».
Или
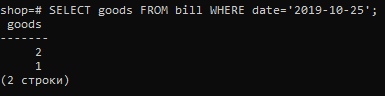
SELECT goods FROM bill WHERE date=’2019-10-25′;В ответ получим 2 и 1.
Условий выбора может быть много, их соединяют оператором AND. Например:
SELECT name FROM goods WHERE (price<200) AND (category= ‘бытовая химия’);
Если вы хотите получить только уникальные значения (то есть чтобы строки, которые вы выводите, не повторялись), достаточно приписать DISTINCT:
SELECT DISTINCT category FROM goods;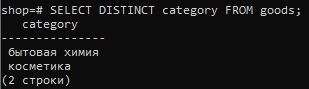
Получим только две строки: косметика и бытовая химия.
Объединение таблиц
С помощью SQL можно не только создавать (CREATE) и удалять (DROP) таблицы, но и объединять их.
Самый простой способ объединения — объединить всё:
SELECT * FROM goods, bill;В этом случае мы получим прямое произведение таблиц. То есть каждая строка одной таблицы склеится с каждой строкой из второй таблицы.
Но даже в нашем примере при таком объединении получится большая и непрезентабельная таблица, не имеющая никакого смысла. Поэтому таблицы нужно объединять по какому-то атрибуту, например по внешнему ключу.
Допустим, нам нужно посмотреть товары и выручку по ним. Для этого выведем столбцы с названием товара, ценой и проданным количеством (из таблицы bill), объединив таблицы по столбцу id из таблицы «goods» и атрибуту goods — из таблицы «bill»:
SELECT name, price, bill.quantity FROM goods, bill WHERE goods.id=bill.goods;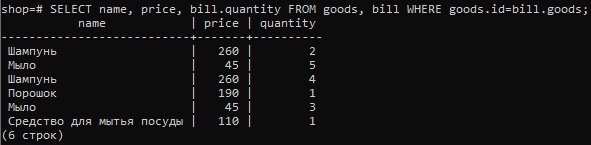
Мы получим таблицу, в которой каждому названию будет соответствовать цена и проданное количество.
Но эта таблица тоже будет неудобной, так как мы получим не суммарное проданное количество, а разбитое по чекам («Шампунь» и «Мыло» встречаются два раза).
Для того, чтобы получить нужный нам результат, сгруппируем данные (GROUP BY) по названию товара и найдем суммарное проданное количество каждого товара (SUM).
SELECT name, AVG(price) AS price_per_one, SUM(bill.quantity) AS quantity FROM goods, bill WHERE goods.id=bill.goods GROUP BY name;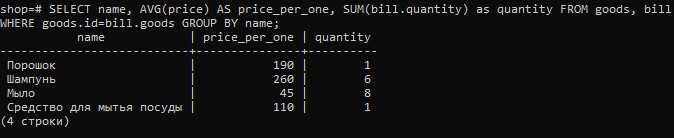
Мы получили то, что нам было нужно: сколько каких товаров было продано и по какой цене. Теперь можно найти выручку по каждому товару, добавив еще один столбец.
GROUP BY всегда ставится в конце запроса. В сгруппированном запросе должны выводиться либо атрибуты, по которым происходит группировка, либо агрегатные функции — SUM, COUNT, MAX, MIN, AVG (среднее значение), — которые выполняются уже для сгруппированных данных.
Именно поэтому в примере вместо обычной цены мы вывели среднюю.
Мы рассмотрели еще один оператор: GROUP BY. Благодаря ему можно группировать данные по любому атрибуту, что упрощает визуальное восприятие и дальнейший анализ.
Еще обратим внимание на оператор AS. С помощью него можно именовать столбцы и новые таблицы, что мы и сделали в примере выше.
Вернемся к соединению таблиц (JOIN). Это очень важный вопрос при работе с базами данных. Объединение делится на внутреннее (INNER) и внешнее (OUTER). Внешнее, в свою очередь, делится на левое (LEFT), правое (RIGHT) и полное (FULL).
По умолчанию при указании [имя таблицы] JOIN [имя таблицы] ON [условие соединения] подразумевается внутреннее соединение. То есть будут выведены те соединения строк, которые удовлетворяют заданному условию.
Например:
SELECT name, AVG(price) AS price_per_one, SUM(bill.quantity) AS quantity FROM goods JOIN bill ON goods.id=bill.goods GROUP BY name;В этом случае мы получим точно такой же результат, как в предыдущем запросе. Выведутся только те товары, которые были проданы.

Если мы воспользуемся левым соединением:
SELECT name, AVG(price) AS price_per_one, SUM(bill.quantity) AS quantity FROM goods LEFT JOIN bill ON goods.id=bill.goods GROUP BY name;то получим не только строки соединения, для которых выполняется условие, но и все остальные строки из первой таблицы (отсутствующие значения из второй таблицы будут заменены на NULL или отсутствовать).
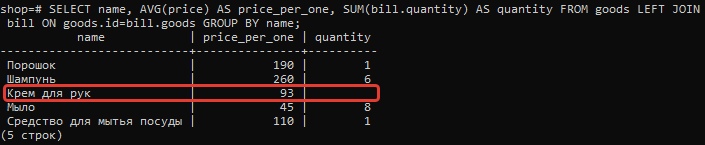
Правое соединение обратно левому. Результатом запроса
SELECT name, AVG(price) AS price_per_one, SUM(bill.quantity) AS quantity FROM goods RIGHT JOIN bill ON goods.id=bill.goods GROUP BY name;будет соединение строк из второй и первой таблицы, удовлетворяющих условию, плюс остальные строки из второй таблицы.
Но в нашем случае результат запроса будет идентичен запросу с внешним соединением (INNER JOIN), так как таблицы связаны по id товара. А это значит, что в таблице bill могут присутствовать только те id товара, которые есть в таблице goods.

FULL JOIN выведет соединения строк, совпадающих с условием, и оставшиеся строки каждой таблицы со значениями NULL. То есть это склеивание правого и левого объединения.
Сортировка
И еще одна из базовых команд SQL — ORDER BY, которая упорядочивает строки. По умолчанию применяется сортировка по возрастанию — ASC. Чтобы ранжировать по убыванию, нужно добавить DESC. Посмотрим на примере:
SELECT * FROM goods ORDER BY price;
Получили сортировку товаров по возрастанию стоимости.
Или:
SELECT * FROM goods ORDER BY quantity DESC;
Поиск совпадений
Познакомимся еще с одной полезной функцией — LIKE или (~). С помощью нее можно находить слова в строках, даты, численные значения. Например, найдем среди производителей общества с ограниченной ответственностью (ООО):
SELECT maker FROM goods WHERE maker LIKE ‘ООО%’;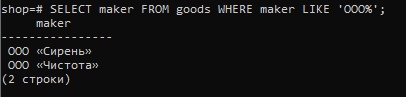
Если то, что мы ищем, может стоять в середине строки, то его окружают знаком % со всех сторон. В нашем случае «ООО» должно встречаться в начале названия, поэтому знак процента стоит после искомого выражения.
Найдем товары, проданные только в первую смену:
SELECT name, date,bill.id FROM goods, bill WHERE goods.id=bill.goods AND bill.id LIKE ‘%1’;
Есть еще очень много полезных функций SQL, которые могут облегчить поиск информации. Например,
BETWEEN [от] AND [до] — выбирает значения только в заданном интервале
IN [множество значений] — выбирает значения из указанного множества
NOT IN [множество значений] — выбирает значения не совпадающие со значениями, указанными в множестве
IS NULL — находит пустые ячейки
Все это только вершина айсберга, но этого вполне достаточно для начального погружения в SQL. Дальше на основе таких простых и интуитивно понятных команд можно строить совсем не тривиальные запросы и выводить удобную для анализа информацию.
Следующий шаг — научиться создавать сложные, многоуровневые запросы и составлять подзапросы. Чем больше у вас будет практики, чем более сложные конструкции вы сможете строить — и тем легче будет работать с базами данных.
Это тоже интересно:
Data Science против Machine Learning
Полный словарь для работы с базами данных
Почему изучать Python и SQL нужно уже вчера?

