
Регрессия: как не делать ложных выводов
 5 мин
5 мин
 885
885  22 Июн 2021
22 Июн 2021 
Основатель и Генеральный директор, SF Education


Интересно, если мама имеет превосходный слух и виртуозно играет на скрипке, будут ли ее дети обладать этими талантами в такой же мере? Или если сегодня вам крупно повезло в картах, будет ли удача на вашей стороне завтра?
Вероятно, герои наших выдуманных историй без сомнений скажут, что 100% будет. Но вот в реальной жизни (к сожалению многих) таких точных результатов не сможет гарантировать никто.
Ответы на похожие вопросы может дать статистика — наука «самая точна из всех неточных».
Один из наиболее распространенных методов статистического анализа, который позволяет сделать вывод о зависимости одних переменных от других — это регрессия. К примеру, есть гипотеза: умение играть в футбол зависит от тембра голоса ребенка и от расстояния от его дома до секции. Эта немного абсурдная гипотеза напоминает всем известный математический анекдот: «Летели два верблюда, один-рыжий, другой-налево. Сколько весит килограмм асфальта, если ежику 24 года».
Но вот если приведенная задача действительно не имеет никакого решения, то вот предположение о маленьких футболистах можно объяснить и математически обосновать. Регрессия как раз и поможет нам разобраться, как это сделать.
Небольшая предыстория
Впервые об этом методе исследований узнали еще в конце 19 века от известного английского ученого Френсиса Гальтона, пытавшегося найти нечто новое в наследовании различных признаков. Сначала сэр Френсис Гальтон измерял характеристики семян растений и пришел к выводу, что потомство было более заурядным, чем его родители (меньше крупных родителей и больше маленьких).
После досконального изучения растений ученый начал измерять все, что только можно придумать, у своих соотечественников: размер носа, глаз, стопы, вес, рост, степень привлекательности, манеру движения и так далее. Гальтону очень хотелось доказать, что характер и умственные способности человека тоже передаются по наследству, как цвет кожи, глаз, строение тела и другие характеристики.
Исследователь решил посмотреть, как связан рост отцов и их детей. Если говорить математическим языком, то рост родителей в его экспериментах — это независимая переменная, а рост детей — зависимая.
Гальтон разделил всех участников эксперимента по группам в зависимости от их роста, рассчитал среднее арифметическое для каждой группы и отметил точки на графике. Затем ученый построил прямые линии, которые больше всего соответствовали траекториям нанесенных точек. Это называется аппроксимацией.
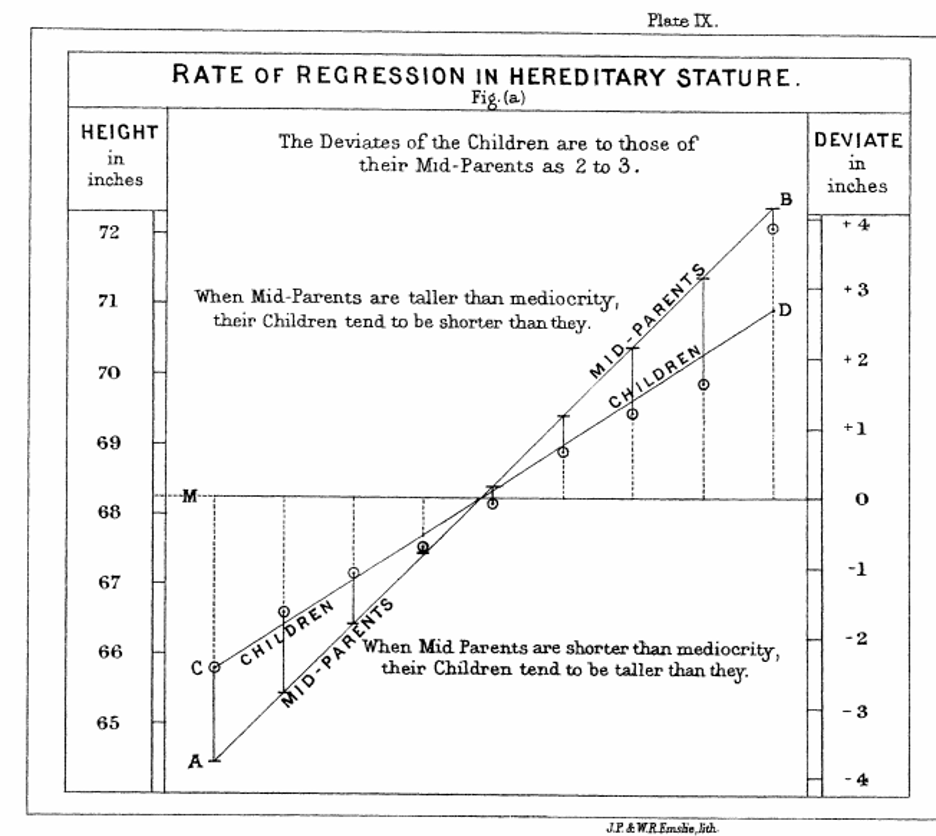
На графике видно, что у высоких родителей рождаются высокие дети, но средний рост сыновей меньше, чем у отцов, и наоборот: у низких родителей рождаются невысокие дети, но их средний рост выше, чем у родителей. То есть средний рост сыновей все больше приближается к среднему значению роста по всей популяции.
Гальтон назвал это «регрессией к посредственности» или «регрессией к среднему», а прямые, характеризующие зависимость переменных, — линиями регрессии.
Это то, что касается исторического появления термина «регрессия» и самого метода «регрессионный анализ».
Дальше начали развиваться различные модели регрессии.
Линейная регрессия
Линейная регрессия — самая простая из всех. Она показывает, как одни переменные зависят от других. То есть можно построить прямую линию таким образом, чтобы она проходила максимально близко ко всем точкам одновременно (как это было проделано Гальтоном в случае с изучением семян и роста детей).
Если мы имеем несколько значений для разных факторов, то линию зависимости одних показателей от других мы можем с легкостью получить. Для этого подойдет метод наименьших квадратов. Он позволяет найти коэффициенты для построения регрессионной линии.
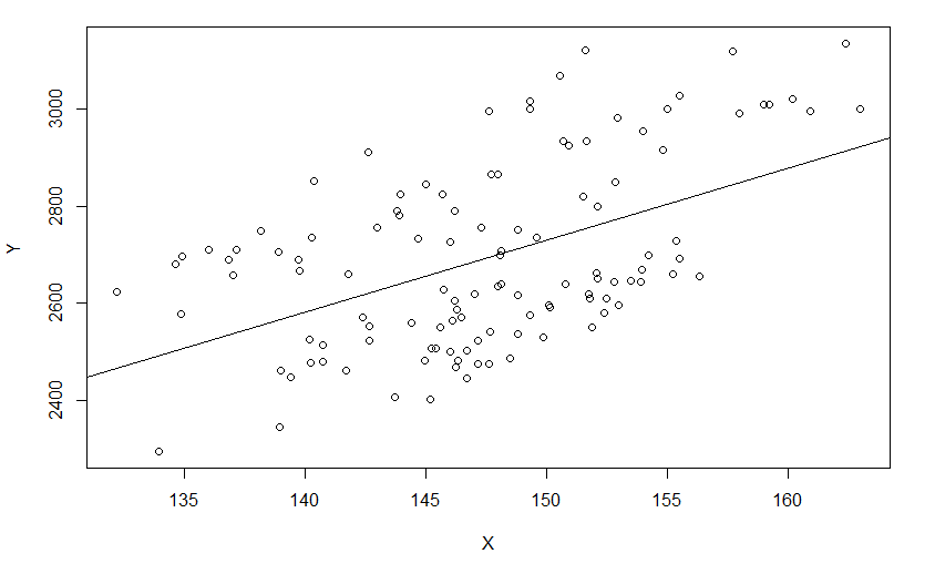
Зачем это нужно? Например, можно оценить эластичность спроса по цене товара, то есть посмотреть, как будет меняться реакция потребителей на изменение цены товара.
Линейная регрессия — отличный инструмент для прогнозирования почти любых процессов:
• Объема продаж. В этом случае мы строим план на определенный период по уже имеющимся данным, предполагая, что тенденции сохранятся.
• Стоимости ценных бумаг. Этот показатель, который зависит от множества факторов. Поэтому и регрессионную модель нужно строить на основе прибыли компании, рентабельности выручки, балансовой стоимости и прочие.
• Загруженности сайтов. В этом случае прогнозирование интереса к веб-сервису позволит избежать излишней нагрузки на серверы и благоприятно скажется на качестве работы.
Логистическая регрессия
Логистическая регрессия — метод предсказания и кластеризации объектов на две группы. Чаще всего используется в тех случаях, когда зависимые переменные принимают значения от 0 до 1, либо переменные дискретные и могут равняться либо 0, либо 1. То есть событие либо случится (1), либо нет (0).
Логистическая регрессия похожа на линейную: ее цель — найти коэффициенты линии регрессии. В логистической модели, в отличие от линейной, используется нелинейная функция, поэтому воспользоваться методом наименьших квадратов уже не получится. Здесь для нахождения коэффициентов регрессии используется метод максимального правдоподобия.
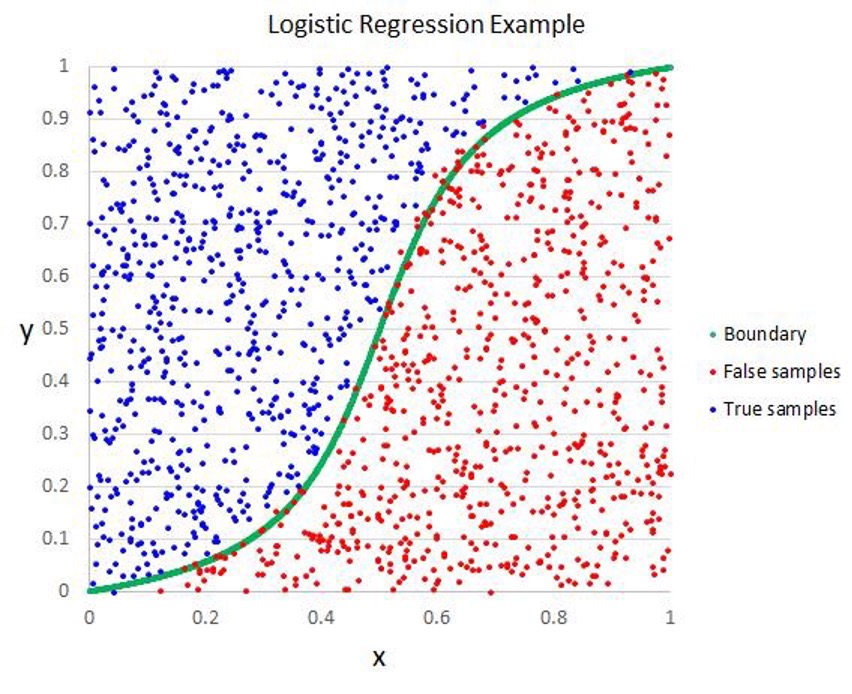
Где пригодится? Логистической моделью можно пользоваться для
• Оценки кредитоспособности заемщиков. Например, зависимая переменная будет равняться 1, если клиент расплатится по кредиту и 0, если нет.
• Определения вероятности достижения цели при каких-то условиях. Например, будет ли выполнен финансовый план при ведении определенной финансовой политики.
• Диагностики финансового состояния компании. Можно оценить влияние таких показателей, как ликвидность, рентабельность, финансовая устойчивость на положение компании.
• Предупреждения состояния банкротства. Метод логистической регрессии позволяет сделать вывод принадлежит ли предприятие к группе банкротов и оценить вероятность возникновения риска банкротства для предприятия.

Полиномиальная регрессия
Полиномиальная регрессия — модель, приближающая данные полиномом k-той степени. Линейная регрессия является частным случаем полиномиальной регрессии, где k=1. Если k=2, то регрессионная линия — парабола, k=3 — гипербола и так далее. Обычно останавливаются на полиноме 5-6 степени.
Эту модель используют в тех случаях, когда мы не знаем, как именно связаны наши данные и когда возникает множественная регрессия (одна зависимая и несколько независимых переменных).

Несмотря на то, что регрессионный анализ очень распространен в качестве метода оценки данных, не стоит всегда верить его результатам. Приведем пример: пусть у очень высоких родителей рождаются просто высокие дети, а у очень маленьких родителей — обычного роста дети. Значит ли это, что рано или поздно все станут одного роста? Ответ: конечно, нет.
Идея регрессии оказалось хитрой ловушкой даже для самых искушенных умов. А все по простой причине — регрессия к среднему не предполагает зависимости от времени. Регрессия действует не только вперед во времени, но и назад. Это значит, что у высоких детей родители обычно чуть ниже ростом, а у низких детей — чуть выше.
Принимать регрессию за какую-то реальную силу, заставляющую какие-то показатели со временем сходить «на нет», значит делать регрессивный ложный вывод (он же ложный вывод Гальтона). В прошлом веке неправильная трактовка регрессии привела к рождению евгеники, фашизма и прочих «социально направленных» учений. Так что делайте только правильные выводы.
Полезные инструменты
Конечно, статистика и наука в целом ушли далеко вперед, и в 21 веке нам не понадобится линейка для измерений и деревянные счеты для нахождения коэффициентов (как во времена Гальтона).
Все популярные модели уже давно реализованы в специальных сервисах и библиотеках, чтобы мы могли ими быстро воспользоваться.
Например, всеми любимый Excel, конечно же, располагает таким функционалом. Можно воспользоваться встроенной функцией ПРЕДСКАЗ, которая вернет значения линейного тренда или же немного «покопаться» в настройках и добавить пакет анализа, где помимо регрессии можно найти много интересных автоматизированных методов анализа данных. Подробнее о встроенных методах Excel можно узнать на нашем открытом онлайн-курсе «Аналитика в Excel».
А мы пойдем дальше.
Если возможностями Excel может пользоваться каждый, то построить регрессию с помощью библиотек Python будет немного сложнее, потому что для этого нужны навыки программирования. Но универсальная библиотека scikit-learn с открытым исходным кодом предоставляет широкий спектр моделей для анализа ваших данных.
С помощью библиотек Python вы сможете не просто провести регрессионный анализ, но и оценить качество модели для ваших данных.
На нашем курсе «Бизнес-аналитик» есть модуль Python, изучив который, вы без проблем освоите все необходимые для работы библиотеки.
Заключение
Эта статья — это стартовая площадка, с которой вы можете начать изучать вопрос прогнозирования более подробно. Если у вас есть вопросы по поводу алгоритмов и механизма работы перечисленных выше моделей, то пишите в комментариях и мы сделаем для вас более подробный разбор каждой темы.

Читайте также:
Что такое регрессионный анализ
Бизнес-аналитик: кто он такой и чем занимается?
Методы прогнозирования в Excel

